
…and how it informs the new coding paradigm for Software Engineers
This article is also published as Part of Ask-Y’s series “What it takes to make AI Native Analytics work in the real world” here.
“Why is Windsurf failing at this cross-component change?” “Would Claude do better for this complex business logic?” “Should I just write this code myself?” These are questions every software engineer has—or should have—as we navigate the new reality of AI-augmented development. In my engineering practice, 80% of my code now comes from AI—but the critical insight isn’t that AI can write code, it’s understanding when to use which tool and why they succeed or fail in different scenarios.

Beneath the surface, Cursor and Windsurf, and Roo Code operate on multi-model architectures that create both opportunities and limitations. Each uses different approaches to solve the fundamental challenge of context management. Cursor provides granular control with its reasoning and apply models, making it ideal for precise modifications but requiring explicit context guidance. Windsurf excels with automatic context detection in standard codebases, handling pattern replication efficiently while sometimes struggling with novel approaches. Roo Code offers transparent token management and targeted precision that gives developers more direct control over the AI interaction.
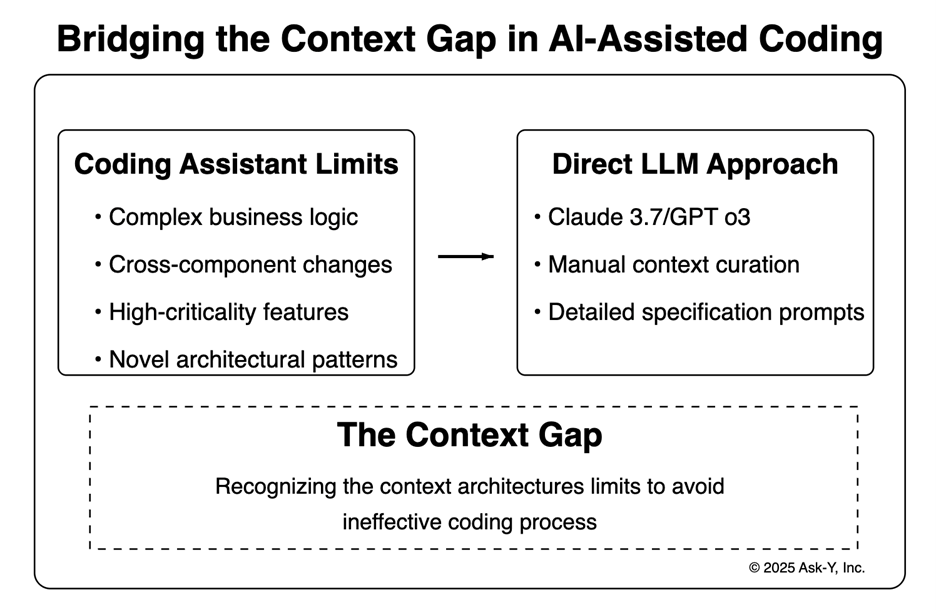
When these tools reach their limits—for complex business logic, cross-component changes, or high-criticality features—I switch to direct engagement with Claude 3.7 or GPT o3, each bringing distinct strengths to different coding challenges. In this article, I’ll share the architectural insights that transformed my workflow, demonstrating how understanding the reasoning/apply model separation helps bridge the context gap that often leads to integration failures and bugs. You’ll learn practical strategies for selecting the right tool based on context requirements, pattern complexity, and business criticality—moving beyond simple prompting to true AI collaboration.
Perhaps most importantly, we’ll explore how this shift isn’t democratizing development as expected, but instead highlighting the value of systems thinking, integration expertise, and debugging across boundaries—skills that remain firmly in the human domain despite AI’s rapid advancement.
What AI has revealed is that writing code was never our true value; it was just one time-consuming task in our palette. As technical implementation details are increasingly automated, the profession’s core skills are now in the spotlight: managing complexity, making judicious trade-offs, and controlling the rich context required for creating harmonious systems. The differentiator now is how effectively we can communicate context to these AI tools—while focusing our own efforts on the architectural vision and integration expertise that have always been the hallmarks of exceptional engineering.
Context and Multi-Model Architecture: Why Understanding It Matters
The effectiveness of my AI-augmented workflow stems from understanding the technical architecture of AI driven IDEs (Integrated Development Environments) like Cursor, which employ a multi-model approach. The core challenge in AI-assisted tasks is context management—a problem that remains mostly unsolved.
The fundamental limitation is that no single model today can practically both fully understand your entire codebase, and efficiently implement precise changes – such a model requires both very strong general reasoning and planning capabilities and very precise ability to change code, all with a very large context windows – even with the ability to handle huge context windows, the actual task is too complex, and existing frontier LLMs are too slow and expensive and inaccurate to be practical. This creates a context gap that engineers must learn to bridge.
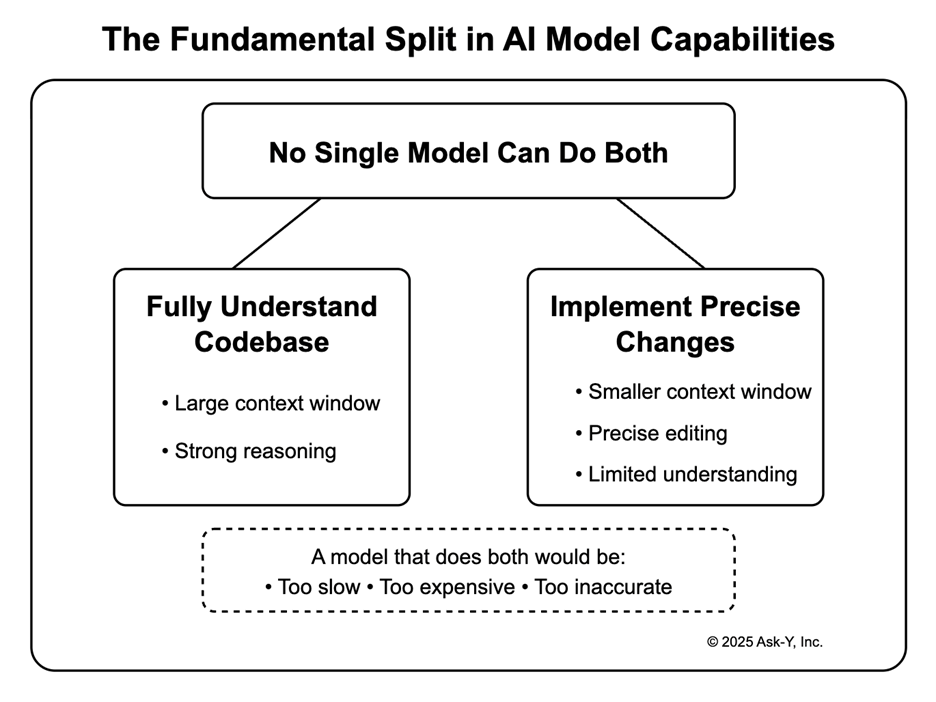
The Multi-Model Architecture
Tools like Cursor address this limitation through a specialized architecture:
- Primary Reasoning Model (Claude 3.5/3.7 Sonnet): This “thinking” model interprets requirements and plans code changes. While it has strong reasoning capabilities, it doesn’t directly write code.
- Apply Model: A separate, fine-tuned model optimized for implementing precise code changes to existing files. It is a fine tuned llama3-70b and it’s faster and more accurate for code changes, but has critical limitations:
- Context System: AI IDEs retrieves and selects relevant code sections for the prompts using vectorized semantic search and pattern-based search techniques. The system manages:
- Vector embeddings of files: Code is converted to mathematical vectors that capture semantic meaning using . For example, a function calculate_total_price(items, tax_rate) and compute_final_cost(products, tax_percentage) would have similar vector representations despite different naming.
- Relevance scoring: Files are ranked by multiple factors. For example: Recently edited files receive higher priority, as do files with stronger semantic matches to the query.
- Context window optimization: Cursor selectively includes code fragments to maximize relevance while minimizing token usage. For instance, it prioritizes recently modified sections while excluding irrelevant parts of the codebase.
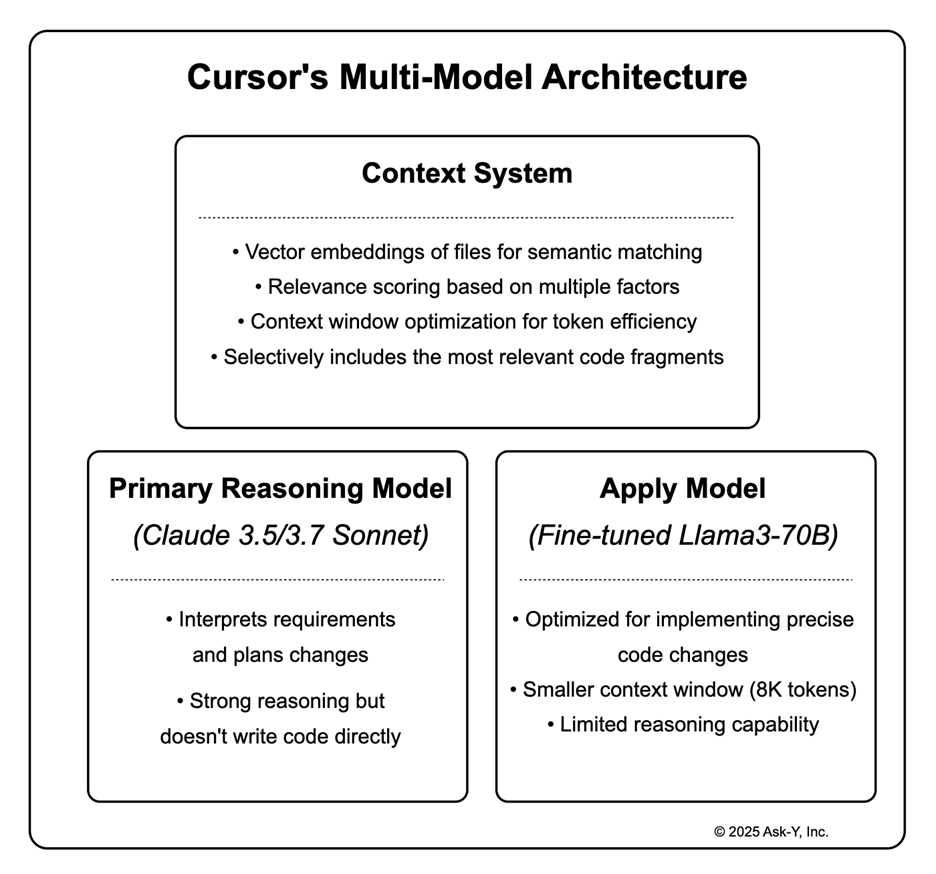
Coming back to the key insight that transformed my workflow: the model that understands your task is not the same model that writes your code, i developed strategies to manage the context disconnect where the reasoning model might comprehend the full requirements, but the apply model operates with limited information, and the existing context systems are unable to bridge this gap.
This architectural split forces me to explicitly manage context handoffs between models. For example, I once asked Cursor to update a data grid component that consumed a filtering service, but the apply model created incompatible filter parameters because it couldn’t see the service implementation, resulting in runtime errors. Understanding this limitation, I now include specific interface examples and explicitly reference related implementation details in my prompts, compensating for the context gap.
Selecting the Right Tool
Understanding the multi-model architecture guides me in when to use each AI coding approach. The key insight is matching your development task to the right tool based on context requirements, pattern complexity, and business criticality.
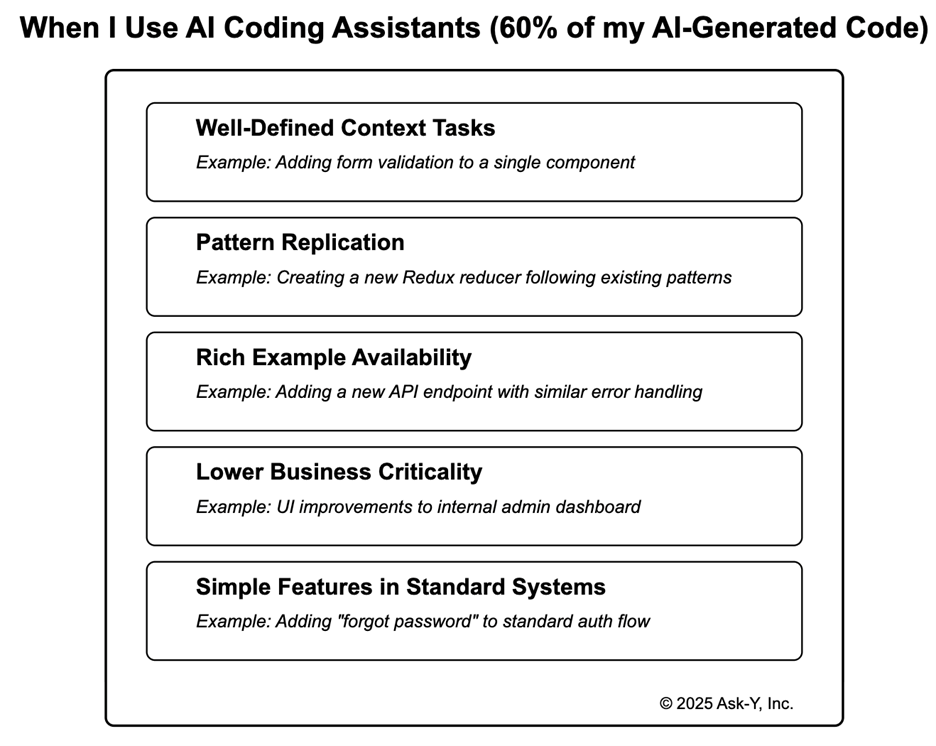
When I Use AI Agents IDEs (60% of the Code I generate with AI)
I leverage apps like cursor/windsurf when technical constraints align with their architecture:
- Well-Defined Context Tasks: Changes limited to specific components where I can explicitly identify all relevant code. Example: Adding a form validation function to a single component where all validation logic is contained within that file.
- Pattern Replication: Implementing established software patterns that ensure code quality. Example: Creating a new Redux reducer that follows the same structure as existing reducers in the codebase.
- Rich Example Availability: When similar implementations exist that the apply model can reference. Example: Adding a new API endpoint that follows the same error handling, authentication, and response formatting as existing endpoints.
- Lower Business Criticality: Components where bugs would have minimal system impact. Example: Implementing UI improvements to an admin dashboard that’s only used internally and doesn’t affect customer-facing functionality.
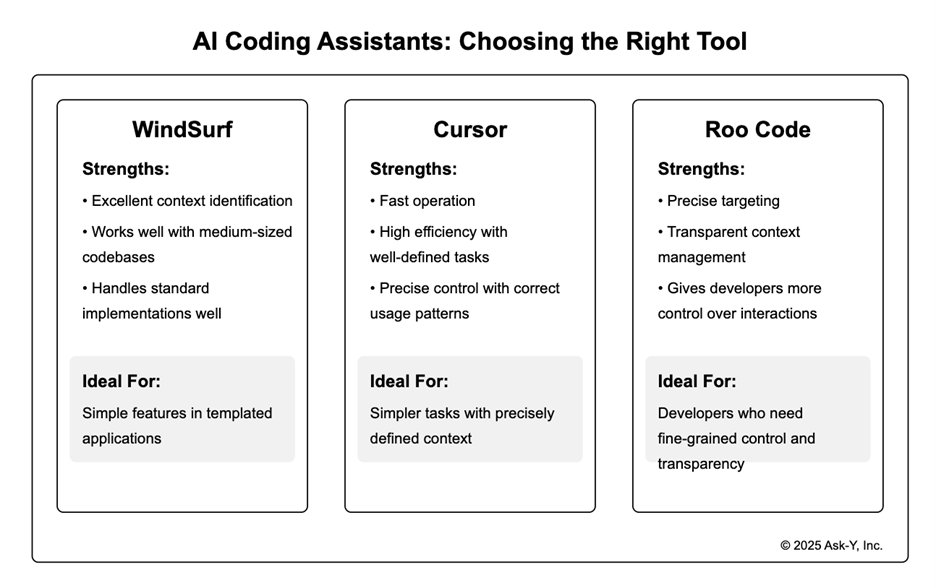
- Simple Features in Standard Systems: I trust IDEs like Windsurf for example, to identify the correct context and write the code when the feature is simple and not at the core of the system, or when the application is very standard, like a templated user registry React app. Example: Adding a “forgot password” feature to a standard authentication flow using common libraries and patterns.
My prompts are engineered to overcome the apply model’s limitations, for example:

What makes this effective:
- Direct file and function references (@header.component.html) create clear anchoring points
- Implementation examples that the ‘apply model’ can follow
- Clear code pattern and styling references maintain code, behavioral, and visual consistency
Comparing AI Coding Assistants: Context Management and Performance
Between the tools, Windsurf excels at identifying the right context for medium-sized codebases with standard implementations, making it ideal for simple features in templated apps, though somewhat slower. Cursor works more efficiently for simpler tasks where I can precisely define the context and can be very fast when used correctly. Roo Code offers precise targeting with transparent context management that gives developers more control over their interactions.
Context Management Capabilities
Windsurf uses intelligent automatic context detection that works particularly well in standardized projects. For instance, when adding a new React component, it can automatically identify similar components and project structures without explicit prompting.
Cursor offers granular control that excels when you need precision. For complex functions, you can explicitly select specific files and components to ensure Cursor has exactly the right context, preventing assumptions based on unrelated code.
Roo Code provides “point-and-shoot precision” with its right-click interaction model, allowing you to quickly add specific code blocks while maintaining transparent token usage.
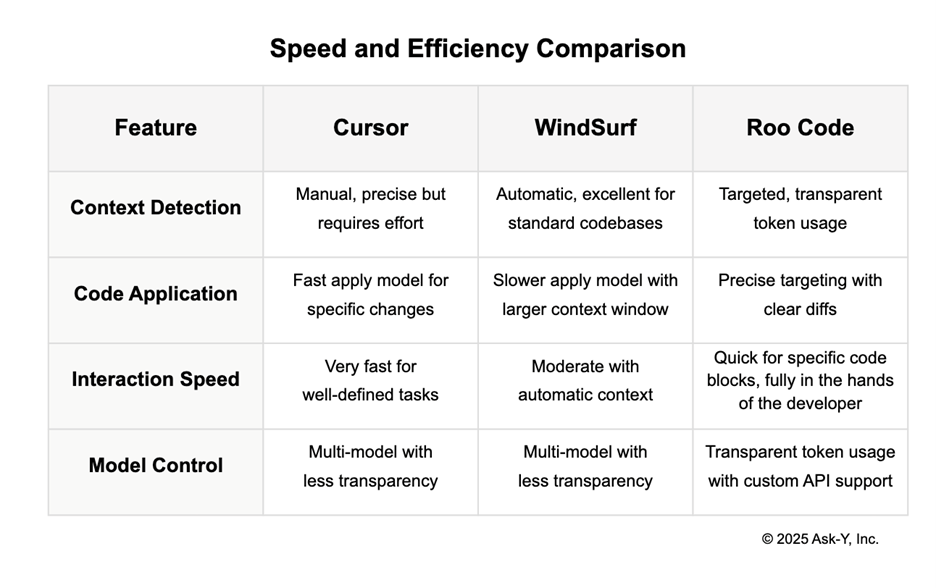
Model Control and Transparency
All three tools use multi-model architectures, but with different approaches:
Windsurf abstracts away model details with its apply model, focusing on delivering a clean experience that writes changes to disk before approval, letting you see results in your dev server in real time.
Cursor provides access to both reasoning models (Claude 3.5/3.7 Sonnet) and specialized apply models for implementing changes, though with less transparency about token usage.
Roo Code stands out by displaying token consumption explicitly when using custom APIs and models, giving developers full control and visibility on which LLM is used, and into how context is constructed and affects costs and model limits.
For standard applications with familiar patterns, Windsurf’s automatic context detection provides a smoother experience. For smaller, well-defined tasks requiring more control, Cursor’s keyboard shortcuts and power features excel. When transparency and explicit context management are priorities, especially for complex modifications, Roo Code’s right-click workflow and token visibility offer the most control.
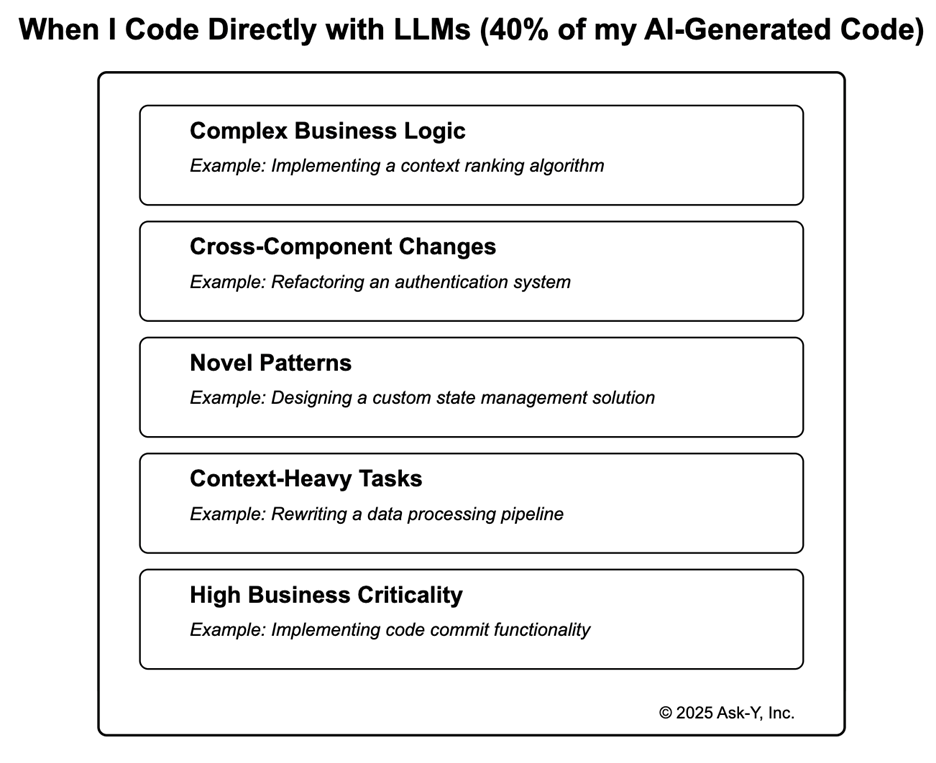
When I Code Directly With LLMs (40% of my AI-Generated Code)
I bypass integrated tools and go directly to Claude 3.7 or GPT o3 when working against the constraints of AI IDEs:
- Complex Business Logic: Tasks requiring deep reasoning about system behavior. Example: Implementing a context ranking algorithm that accounts for user history, data dependencies, and use multiple services.
- Cross-Component Changes: Modifications spanning multiple interdependent files. Example: Refactoring an authentication system to support both OAuth and passwordless login that requires coordinated changes to backend APIs, database schemas, and frontend components.
- Novel Patterns: Creating new approaches without existing examples. Example: Designing a custom state management solution for a specific performance optimization that doesn’t follow Redux or other established patterns in the codebase.
- Context-Heavy Tasks: When complete system understanding is crucial. Example: Rewriting a data processing pipeline that interacts with multiple third-party services and needs to maintain transaction integrity across system boundaries.
- High Business Criticality: When bugs would significantly impact users or the business. Example: Implementing code commit functionality in an developer application where errors could directly impact everything the user does and cause compliance issues.
For these tasks, I handle planning and architecture myself, then create detailed prompts for each code component with detailed specifications and manually curated context. I provide complete code files and references as context, to get individual code components written properly by the LLM, then manually integrate and test them.

While slower, this approach ensures system control and prevents costly bugs that often emerge from letting AI handle the entire implementation.
Claude or GPT – Who Is the Better Code Developer?
Understanding each model’s strengths helps you choose the right one:
For precise implementation with complex code integration, I use GPT o3 because it:
- Follows explicit instructions with high accuracy (e.g., “insert this function here and leave the rest untouched”)
- Handles complex merges and keeps critical elements intact when rewriting files (like combining two data‑import scripts without losing a single flag)
- Produces consistent code with fewer unexpected changes (diffs stay small and predictable)
For tasks requiring deeper reasoning, I use Claude 3.7, as it better:
- Understands complex coding problems and architectural implications (it can spot why a new handler might break existing auth flow)
- Implements intricate business logic with fewer errors (think multi‑currency order routing or layered discount rules)
- Provides clearer reasoning about potential issues (it walks through edge cases and explains how to patch them)
Old School Manual Coding: The Other 20% of the Code
This is not a negligible percentage. It’s not easy to go back to ‘manual’, but I often find this is the better option for different reasons:
- I need to write a critical capability, like introducing a new data structure, and I’m unable to fully specify it to the LLM—it’s just easier to start writing it. Example: Creating a custom caching mechanism for frequently accessed datasets that optimizes memory usage based on specific access patterns of our analysts.
- I need to tune details that LLMs tend to get wrong, like HTML and CSS. Example: Fine-tuning the data studio’s dashboard layout to ensure visualizations resize correctly when analysts are working with split screens or comparing multiple datasets side-by-side.
- I work on changes that require surgical modifications in several files, and it’s harder to define the exact changes and all the change points. Example: Adding comprehensive error tracking across the data pipeline UI that requires inserting consistent error handling in dozens of component files while maintaining the existing state management approach.
- I implement some code as part of my definition for the LLM and end up writing it. Example: Starting to outline a custom drag-and-drop interface for analysts to build data transformation workflows and finding it faster to implement the core interaction logic myself than explain all the nuanced behaviors needed.

The Real Bottlenecks Remain Human
The shift to AI-generated code reveals an important truth: pure code production was never the true bottleneck in software development. Despite the likely prediction that soon 99% of code will be AI-written, the most challenging aspects of software engineering remain distinctly human domains. System design and integration between components require holistic thinking that current AI struggles to replicate—for instance, understanding how a new notification service impacts both database load and user experience across mobile and web platforms. Bug investigation demands forensic reasoning across system boundaries, like tracing an intermittent payment processing failure through APIs, databases, and third-party integrations. Handling edge cases requires anticipating scenarios not explicitly defined, such as managing connectivity issues during multi-step workflows for remote users.
This reality has transformed our hiring focus as well: we now prioritize candidates who demonstrate systems thinking and debugging prowess over routine technical skills. Our technical interviews have evolved from coding exercises and algorithm puzzles to scenarios like “explain how you’d diagnose this cross-service data inconsistency” or “design a system that gracefully handles these competing requirements.” The most valuable engineers aren’t those who write the cleanest functions, but those who can articulate trade-offs, anticipate integration challenges, and bridge technical capabilities with business requirements—skills that remain firmly in the human domain despite AI’s rapid advancement.
The Widening Talent Gap
Counterintuitively, AI-augmented development is magnifying rather than diminishing the value gap between engineers. As routine coding tasks become automated, the profession is splitting into two tiers: those who excel at system thinking, debugging complex interactions, and understanding product needs versus those who primarily coded without these broader skills. Top engineers now leverage AI to rapidly test architectural hypotheses while focusing their expertise on system integration, behavior prediction, and edge case management. Their value comes from superior product intuition, cross-functional communication, and the ability to bridge technical and business concerns. Meanwhile, engineers who historically relied on coding proficiency without developing these systems-level capabilities find themselves with diminishing comparative advantage, regardless of how well they can prompt AI tools.
The mythical “10x engineer” concept is becoming more pronounced, not less, in the AI era. AI tools don’t transform average engineers into exceptional ones—they amplify existing differences. A senior engineer who understands architectural patterns can use AI to implement robust solutions quickly, while less experienced developers generate seemingly functional code that introduces subtle bugs they can’t identify. “Vibe coding”—prompting for solutions without understanding what’s generated—creates a dangerous productivity illusion with hard limits. As systems grow, these engineers become trapped debugging AI-introduced issues they lack the mental models to diagnose, widening the performance gap between the most and least effective team members.
Making the Product Work in the Real World: The Final Frontier
Perhaps the most persistent challenge in software development—and the area most resistant to AI automation—is making systems work reliably with users in unpredictable real-world environments. Handling various user needs, unexpected behaviors, real-world system complexities, and resolving conflicts between competing requirements all require iteration, time, judgment, communication and management skills, prioritization intuitions, and adaptive problem-solving that current AI systems still cannot match. Product managers and engineers who excel at bridging this gap between theoretical implementation and practical reality are becoming increasingly valuable, as their expertise addresses the final mile problem that separates functioning code from successful products.
Bridging The Context Gap for Data Teams with Ask-y
Our experience with AI code assistants revealed a fundamental truth: the context gap remains the primary challenge in AI-augmented workflows. This insight directly shaped our approach to Ask-y, our Multi-agent solution built specifically for data teams.
Just as software engineers’ value wasn’t in writing code but in systems thinking and integration, data professionals’ core value lies in their domain knowledge, data, numbers and business intuitions, and judgment—not in implementing data connections, statistical methods or writing queries. Ask-y leverages our Joint Associative Memory (JAM) architecture to bridge this context gap, learning which elements of a data environment matter most for different analytical tasks. When an analyst explores campaign performance patterns, for instance, JAM doesn’t just surface similar analyses but learns which contextual elements—data structure, business constraints, validation methods—were most predictive of successful outcomes.
Unlike black-box approaches, Ask-y maintains complete transparency, giving data teams full control on both the context and the resulting components. This keeps human judgment central while removing technical barriers that slow hypothesis testing and exploration. The result is an environment where data professionals focus on methodological decisions and interpretation while Ask-y manages the LLMs that handle the technical tasks —preserving the analyst’s essential role while dramatically accelerating their ability to translate insights into business value.
…in Part 1 of this series, we explored “What it takes to make AI Native Analytics work in the real world”.
… in our next article we will look at how analytics workflows call for different scaffolding around LLMs to effectively leverage the benefits of generative AI and how Ask-y sees that changing the jobs of Analysts.
Link to the article on LinkedIn.