When we think of Native AI Assistants today, the first thing that comes to mind are coding assistants like GitHub Copilot, Cursor, and WindSurf. These tools have quickly become indispensable for many developers, fundamentally changing how software is written. But as transformative as these coding assistants are, they represent just one facet of how AI can empower technical work.
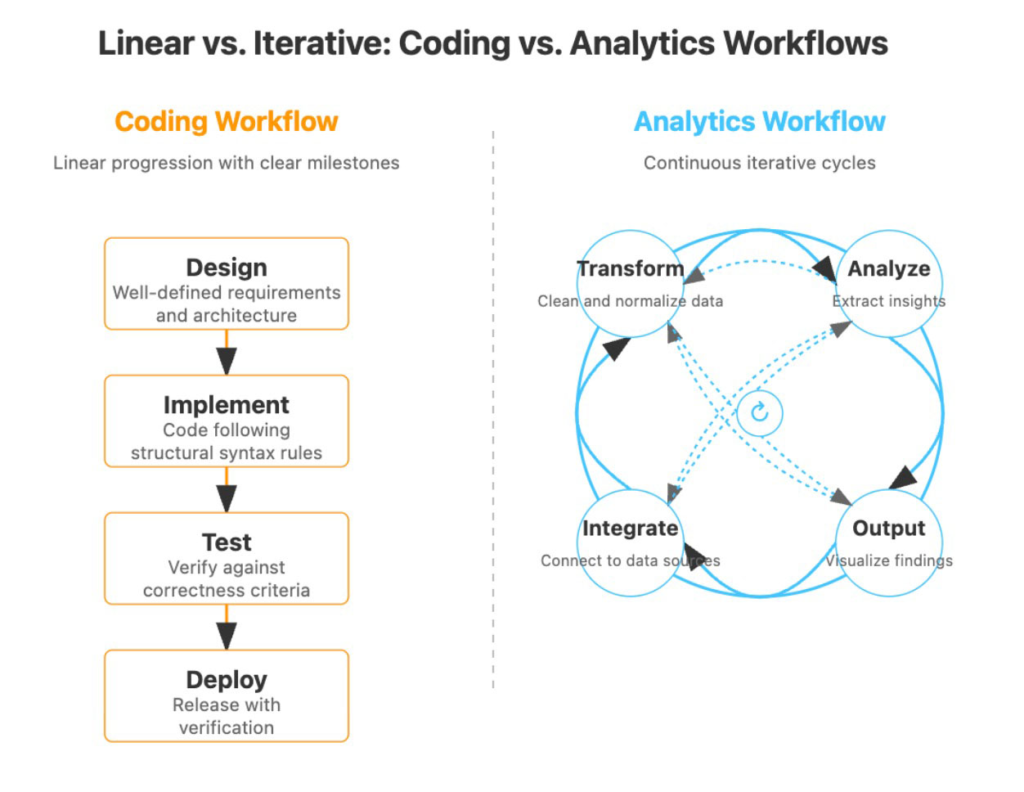
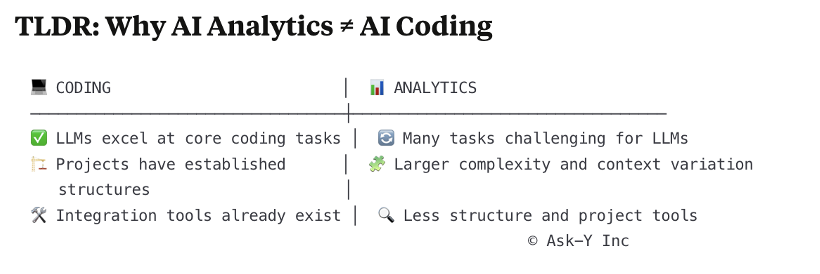
Native AI analytics has to go far beyond coding assistants because the workflow of a typical analytics project is fundamentally different from the software development process. While code follows structured syntax and has clear execution paths, analytics work involves ambiguous problem definition, domain-specific knowledge integration, and complex reasoning about data relationships that often can’t be explicitly programmed.
To understand the unique challenges of building an AI-native analytics platform that works for complex real world analytics projects, we will first look at how current coding assistants work—they represent the most advanced AI-native tools for technical work available today. By understanding their capabilities and limitations, we can better appreciate what it takes to build an AI-native analytics platform that transforms how organizations derive insights from their data.
Ask-Y is pioneering this approach, building not just an AI-native product but an AI-native company where the entire team—from engineers and non engineers—actively engages with AI tools daily (more details here if you are interested). This cultural foundation provides unique insights into how AI can be meaningfully integrated into analytics workflows, creating solutions that think like human analysts rather than just executing predefined queries.
In this series of articles, we’ll share our understanding of how leading coding assistants like WindSurf and Cursor handle Project Management, Memory & Context and Disambiguation, examine why analytics presents distinct challenges from coding, and outline the building blocks Ask-Y is architecting to address the foundational technology challenges that come with solving for analytics workflows.

The future of analytics isn’t just automating queries—it’s creating true AI collaborators for the complex journey from data to insight.
Managing Memory, Context, Disambiguation and Workflow challenges
Code Assistant Architecture: A Springboard for Understanding Analytics-Specific AI Needs
We’re going to look at how code assistants work so we can focus on how AI-native analytics platforms need to be specifically designed for analytics workflow needs. At Ask-Y, we primarily use WindSurf for code generation but also regularly work with Cursor and the open source Roo, so we’ll focus on these leading tools to understand the foundations of AI-assisted technical work.
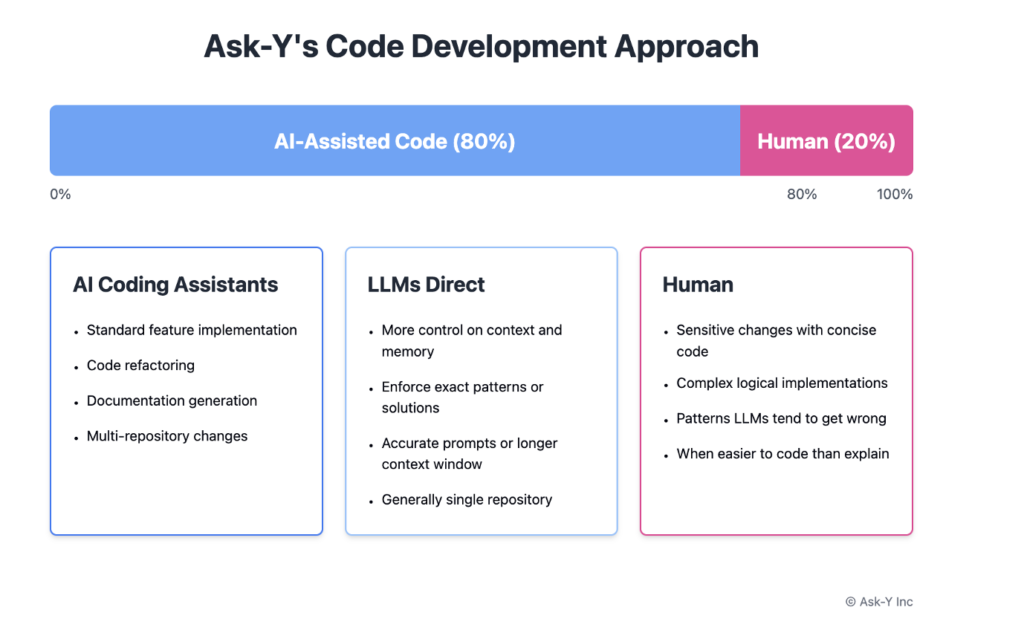
Over 80% of our code has been written either with AI coding assistants or directly with LLMs. We primarily use coding assistants for standard implementations and multi-repository changes. We use direct LLM interaction when we need precise control over context and memory, need to enforce specific patterns, or require more accurate prompts with longer context windows – typically within a single repository. Our human developers handle sensitive changes with concise code and cases where writing code is faster than explaining the requirements. Humans also write code that contains complex logic or uses patterns that LLMs struggle with. This includes both sophisticated designs like shared registry patterns and simple tasks like API calls where LLMs lack full context, or when using libraries where LLMs frequently make mistakes.
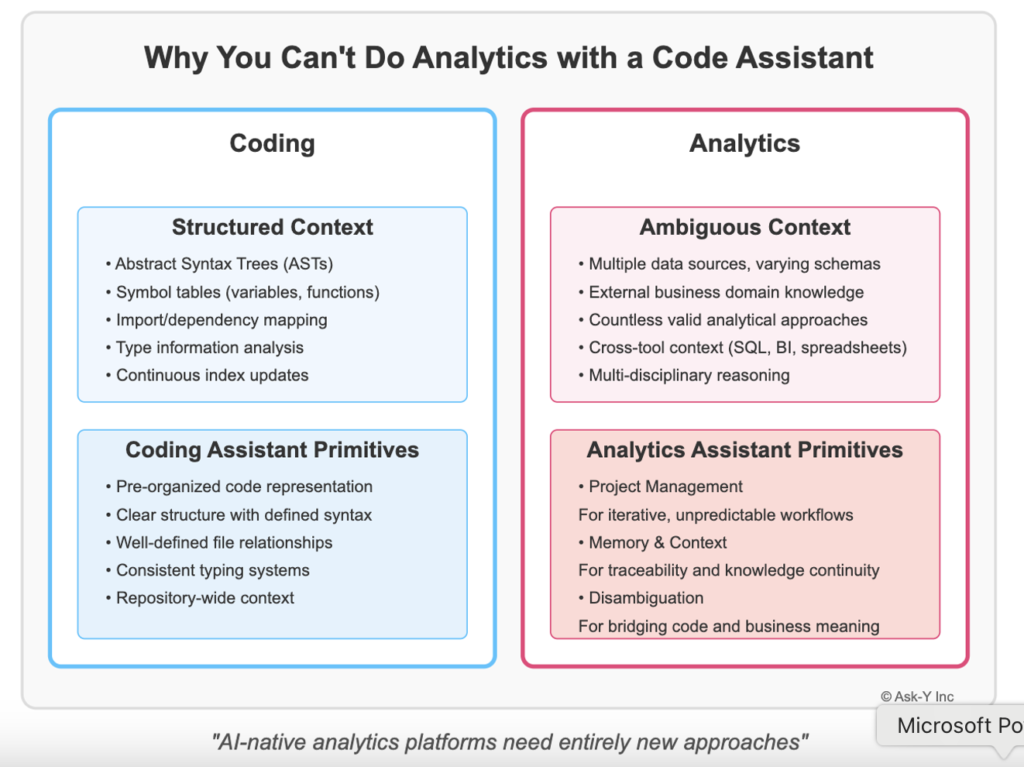
How Code Assistants Leverage Structure: A Contrast to Analytics Complexity
WindSurf, Cursor and Roo are built on top of Visual Studio Code’s architecture, which means they inherit VS Code’s powerful approach to indexing repositories and code and existing infrastructure and protocols for plug-ins like LSP. This foundation is crucial to understanding how these assistants function. Visual Studio Code uses a sophisticated indexing system that:
- Creates abstract syntax trees (ASTs) that represent the structure of code files
- Maintains a symbol table that tracks variables, functions, classes, and their relationships
- Indexes imports and dependencies across the entire codebase
- Analyzes type information where available to understand data structures
- Monitors file changes to keep these indexes continuously updated
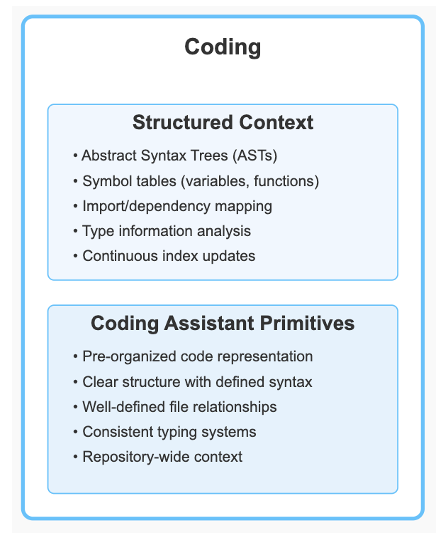
This indexing system provides coding assistants with a rich structural understanding of codebases that goes far beyond what would be possible by simply processing raw text.
When these AI assistants generate completions or suggestions, they’re working with this pre-organized representation of the code, which helps them maintain consistency and accuracy.
In stark contrast, analytics projects operate in a fundamentally different environment. While code has a clear structure with defined syntax rules and typing systems, analytics workflows involve:
- Multiple data sources with varying schemas, quality, and update frequencies
- Business domain knowledge that exists outside any formal structure
- Analytical questions that can be phrased in countless valid ways
- Context that spans across tools (SQL, BI platforms, spreadsheets, presentations)
- Reasoning that combines mathematical, statistical, and domain-specific approaches
Unlike code repositories with well-defined file structures and relationships, analytics knowledge is distributed across databases, documentation, team knowledge, and business context.
There is no equivalent to VS Code’s indexing system for this diverse analytics ecosystem. While frameworks like DBT can be used to organize some of that complexity, they require significant engineering efforts and are limited to SQL code.
To illustrate this difference with a simple example, let’s look at the build process for a simple coaching app for Brazilian Jiu Jitsu competition training versus the build process of an analysis of the competitors performance versus attendance to classes at the academy.
The coach runs a competition class and captures his live comments on student’s training with speech to text, those comments get parsed by an LLM and result in this table:
My first step is to use Lovable (a web design and development agent) to build a prototype that will give me a basic file structure and a starting point. My first prompt gets me a basic prototype that I can synch to Github and further edit with a code editor. This took about 5 minutes and was done fully autonomously by Lovable.
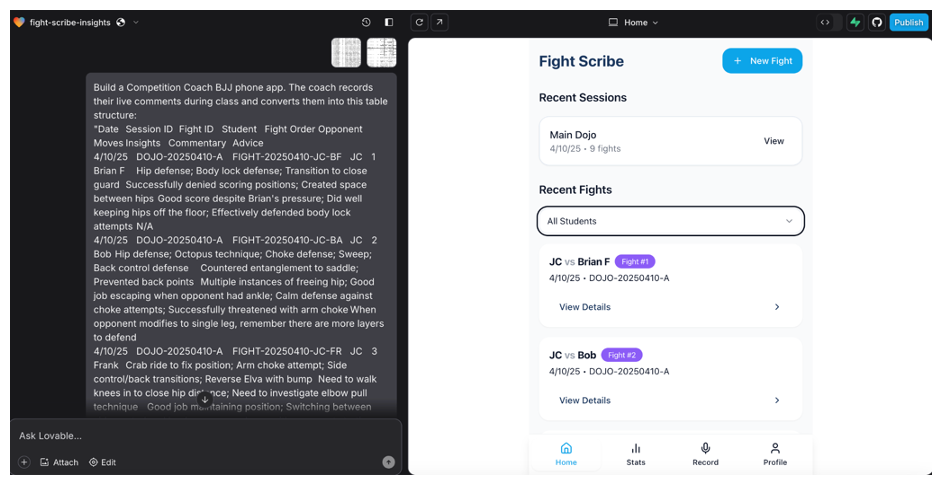
Windsurf opened the app repository without issues, indexed all the files (on the left) and was ready for me to start working on getting the prototype closer to specifications. Based on my first prompt “rename the app to…” (top right), Windsurf is leveraging the file structure to analyze what code needs to change including dependencies etc.

Let’s contrast this with the coaches’ question:
– Do students do better in competition training when they attend a large variety of classes? If so, are there any classes that make more difference?
– For example, do students who attend Wrestling classes perform better in the early phases of a fight?
To answer, the analyst (me…) needs to merge attendance data with coaching data and match records for each student, so my first step is to extract attendance data and load it into Excel as a separate sheet.
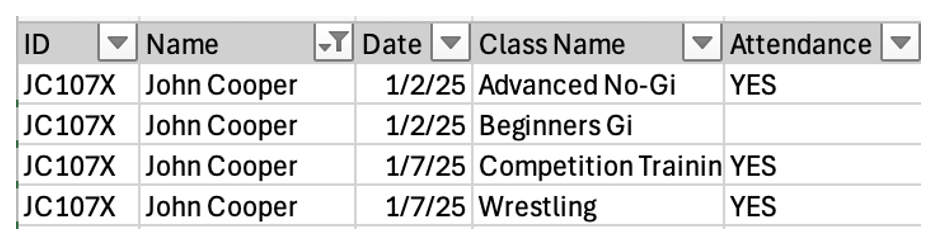
My second step is to try and merge the coaching data set and the attendance data set. I need to make a decision about what level I need the merge to happen, this decision depends on my analysis of the data fields needed to answer the coach’s question.
Unfortunately the coaching data doesn’t have a field that matches well with the attendance data, instead I need to reach out to the coach and ask them for a matching table, or do some fuzzy matching based on the first letters of ID+First Name+”attends competition classes”. The judgment call about this and how good the matching process is is what will make or break the analysis.
Once I manage a sufficiently good matching process, I need to deal with the missing data in the “attendance” column. What do the empty cells mean? Did John not attend Beginners Gi class? Or is this some quirk of the attendance tracking system? Without context I need to make a decision about how to handle the missing values.
At this point we have a number of assumptions in the data, we’ll have to keep these in mind as we progress in our analytics process. Beyond the technicalities of the data preparation, I also need to include real world knowledge in my analysis. For example, I need to know what the belt color system means to avoid trivial “insights” like “higher belt students consistently win against lower belt students”.
This fundamental difference means that AI-native analytics platforms need to build entirely new approaches to organizing and contextualizing information—we can’t simply repurpose the architecture that makes coding assistants effective.
Architecting Intelligence for Analytics Workflows
As we’ve explored so far throughout this article, while coding assistants provide an excellent model for AI-augmented technical work, analytics requires fundamentally different approaches to solve its unique challenges. The world of analytics consists of ambiguous requirements, ever-evolving business contexts, and complex domain-specific reasoning that cannot be addressed simply by adapting tools designed for structured coding environments.
We’ve identified three critical building blocks needed to create truly effective AI-native analytics platforms:
Project Management (Riff ML)
Unlike coding projects with clear syntax rules and execution paths, analytics projects follow non-linear workflows with constantly shifting priorities and requirements. Riff ML provides the foundation for keeping complex analytics projects on track by:
- Dynamically adjusting to shifting business priorities and evolving data landscapes
- Maintaining coherence across multiple stages of analysis that may involve different team members
- Tracking the reasoning chain from initial business question to final insight delivery
- Facilitating handoffs between human analysts and AI assistants at appropriate points in the workflow
Workflow management including task template and data structures and extensive tracking of project progress enable effective management of analytics projects.
Riff ML doesn’t just manage agents and tasks —it leverages this know-how to inject relevant context in the agent’s process and inform decisions about the agent’s next action.
Memory & Context (JAM)
While code repositories benefit from structured file systems and well-defined symbols, analytics knowledge is distributed across databases, documentation, and team knowledge. JAM (Joint Associative Memory) addresses this challenge by:
- Creating persistent, searchable memory across analytics projects and interactions
- Indexing not just code but business context, data relationships, and domain knowledge
- Connecting disparate information sources ranging from SQL queries to presentation slides
- Evolving knowledge representations as business terminology and priorities change
JAM serves as the collective memory that makes analytics AI truly context-aware across the organization.
Disambiguation (Mingus)
Analytics code often presents significant readability challenges that create barriers between technical implementations and business understanding. MINGUS (Modeling Intent in Natural Language into Granular, Unambiguous Scripts) addresses these challenges by:
- Creating an interpretative descriptive language that serves as a semantic layer between natural language and code
- Translating complex code into human-readable explanations that non-technical users can understand
- Resolving the ambiguity inherent in mapping business variables to technical implementations
- Detecting and resolving loops in reasoning or implementation to ensure clarity
- Providing bidirectional modification capabilities that allow users to edit code through natural language
Mingus bridges the technical-business divide not just through intermediate language representation, but by enabling true code-to-text explanation and semantic mappings that make analytics truly accessible across the organization. Unlike code assistants that focus primarily on writing correct syntax, Mingus creates a two-way semantic layer that democratizes analytics understanding and modification.
The Path Forward
Building an AI-native analytics platform requires more than just integrating an LLM into existing tools. It demands a ground-up architecture that addresses the unique challenges of analytics workflows. By focusing on these three foundational elements—Project Management, Memory & Context, and Disambiguation—we’re creating systems that think like human analysts rather than just executing predefined queries.
The future of analytics isn’t about replacing human analysts but empowering them with AI collaborators that understand the full complexity of the journey from data to insight. We’re building both the technology and the organizational culture needed to make this vision a reality.
As AI continues to transform knowledge work, the future in analytics won’t be simply automating existing processes but reimagining what’s possible when human creativity meets AI’s capacity for context management, process coordination, and ambiguity resolution.
…in our next article, we’ll go deep on coding assistants in action, how they change the work of Software Engineers and how Ask-Y is changing what we’re looking for when hiring Software Engineers.
… in a further article we will look at how analytics workflows call for different scaffolding around LLMs to effectively leverage the benefits of generative AI and how Ask-y sees that changing the jobs of Analysts.
Link to the article on linkedIn.