Just as the rise of foundation models created the “AI Engineer” role (1) transforming software engineers productivity (2), we’re witnessing the rise of the “AI Analyst”. Data Analysts who successfully leverage LLM capabilities are experiencing fundamental role transformations of where and how well analysts operate in the analytics stack.
(1) I highly recommend this article if you’ve never read it https://www.latent.space/p/ai-engineer
(2) More here.
The full- stack shift of the AI Analyst
Data Analysts who successfully leverage LLM capabilities are seeing a role expansion fueled by increasingly sophisticated LLMs coding capabilities and their absorption of analytics knowledge coupled with LLMflation (the rapid decrease of inference cost for equivalent LLM performance fueled by the highly competitive Foundational Model market )
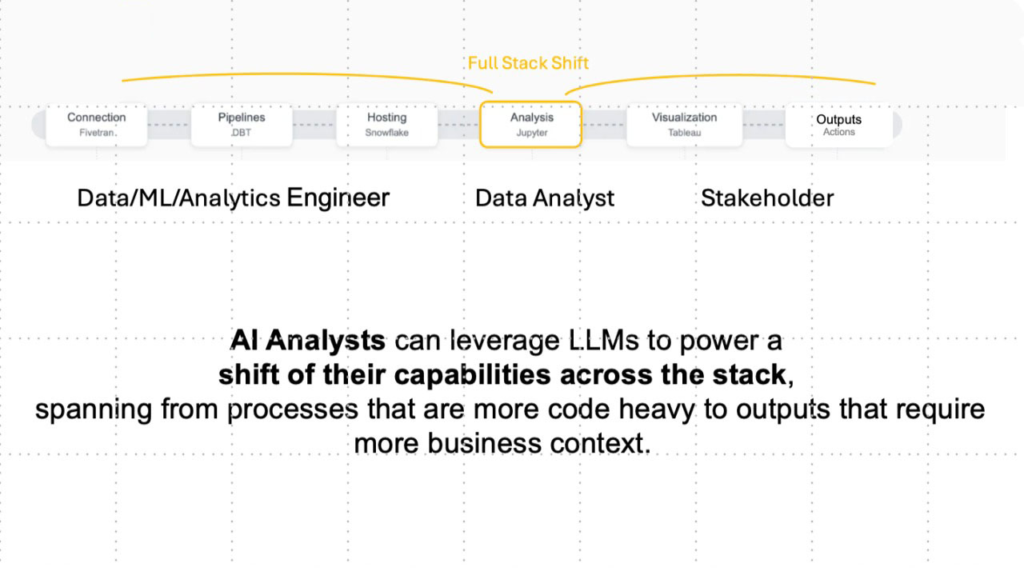
Traditional Data Analysts operate around the middle of the analytics process, between the creation of the data layer on the left (where data gets captured to model business operations) and the translation of analytics results into options for business decisions on the right.
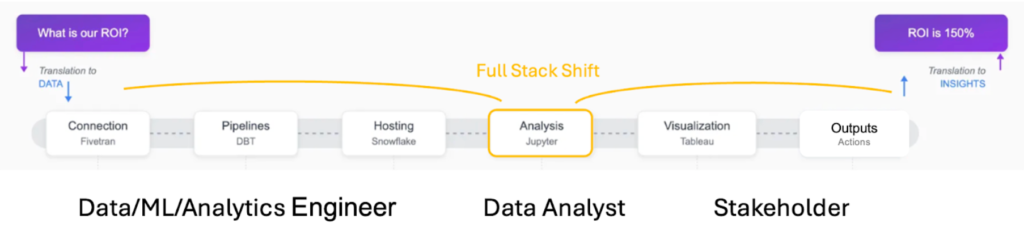
AI Analysts can leverage LLMs to power a shift of their capabilities across the stack, spanning from processes that are more code heavy like connecting to APIs and building pipelines to outputs that require more business context like translating the results of a ML model into options for actions within a particular business domain.
AI Analysts need to master the tools and techniques that power sophisticated leveraging of LLMs in Analytics. Naive usage quickly shows limits and is at best providing trivial results, at worst introducing errors in the analysis because of faulty code, lack of context or just plain wrong math.
We’ve all uploaded a csv into Clause and asked it to give us insights. Though on the surface the results may be impressive, a closer look quickly shows that our roles as Analysts aren’t going anywhere anytime soon.
What makes a Data Analyst and AI Analyst?
The tools and techniques Data Analysts need to get good at to leverage LLMs in their workflows include softer and harder skills:
- Understanding how different LLMs work: I believe this part is key to get the best out of every model for different types of tasks. Beyond understanding the basics of training, inference, context windows, memory and reasoning, AI Analysts need to develop and maintain a solid practical experience of how each model embeds data and performs analysis, both from a conceptual and technical point of view.
- Prompt and Context Engineering: effective communication with LLMs is a skill that involves an understanding of optimal prompt structure and knowledge of how to inject relevant context into prompts as the analysis progresses. This is where practical experience with each model is probably the most important: avoiding and breaking loops without resetting a session, refreshing relevant contextual information to maximize inference performance, building in guardrails, avoiding hallucinations etc are all skills that are part of the AI Analyst’s arsenal.
- Code Generation: the most developed part of models application to professional workflows, code generation with LLMs is in no way a passive process where the Analyst simply gets the model to write code for them, it is a skill that involves knowing when to use a coding assistant, when to go to the model directly and when to write the code manually (More here)
And above all critical thinking. This to me goes back to point 1 “ Understanding how LLMs work”: magical thinking isn’t going to carry us very far, having a great new tool that can do amazing cool things doesn’t mean AI Analysts are free to delegate their thinking to the models, that’s a recipe for a fast crash.
Developing these skills involves a lot of trial and error, reading around and finding good resources to learn, trying new tools and generally flexing your self-starter muscles…a throwback to the early 2000s when we were figuring out Digital Analytics using tools that for the most part didn’t even have a manual in a world that’s hadn’t yet invented social media. This feels to me very much like that: an exciting new world where there is a lot to learn, create and develop if you can find the right place to hone your skills.
So how do you get a job as an AI Analyst?
The Greatly Confused Convergence: Analysts are NOT Software Engineers
We are witnessing a fundamental blurring of lines between AI Analysts and AI Engineers, revealing deep organizational confusion about AI’s role in analytics workflows.
Scroll through any tech job board and you’ll find “AI Analyst” positions demanding TensorFlow expertise, model deployment skills, and production ML pipelines—engineering competencies masquerading as analytical ones.
This isn’t just semantic confusion; it’s a symptom of organizations frantically trying to adapt to a world where Python serves both pandas and PyTorch and where LLMs dissolve the boundaries between using and building AI. Yet beneath this confusion lies an undeniable truth: AI is fundamentally transforming what it means to be an analyst, demanding new skills in prompt engineering, context curation, and semantic reasoning that traditional SQL-writing analysts never needed—creating a genuine “AI Analyst” role with expanded capabilities but still an Analyst, not a Software Engineer.
Software Engineers build software, Analysts support business decisions with data driven insights.
Look at actual AI Analyst job postings and you’ll find a pattern of confusion between skill requirements: organizations are asking for “analysts” who will build infrastructure that can support analysis using LLMs AND perform analysis using LLMs. Confusing these two skillsets has an added layer of risk: Engineering organizations and Data teams don’t have the same workflows or processes, trying to put an engineer in a data team or an analyst in a development team is bound to create fraction as engineers have essentially linear deterministic workflows and analysts have distinctly circular non-deterministic workflows ( more on that here)
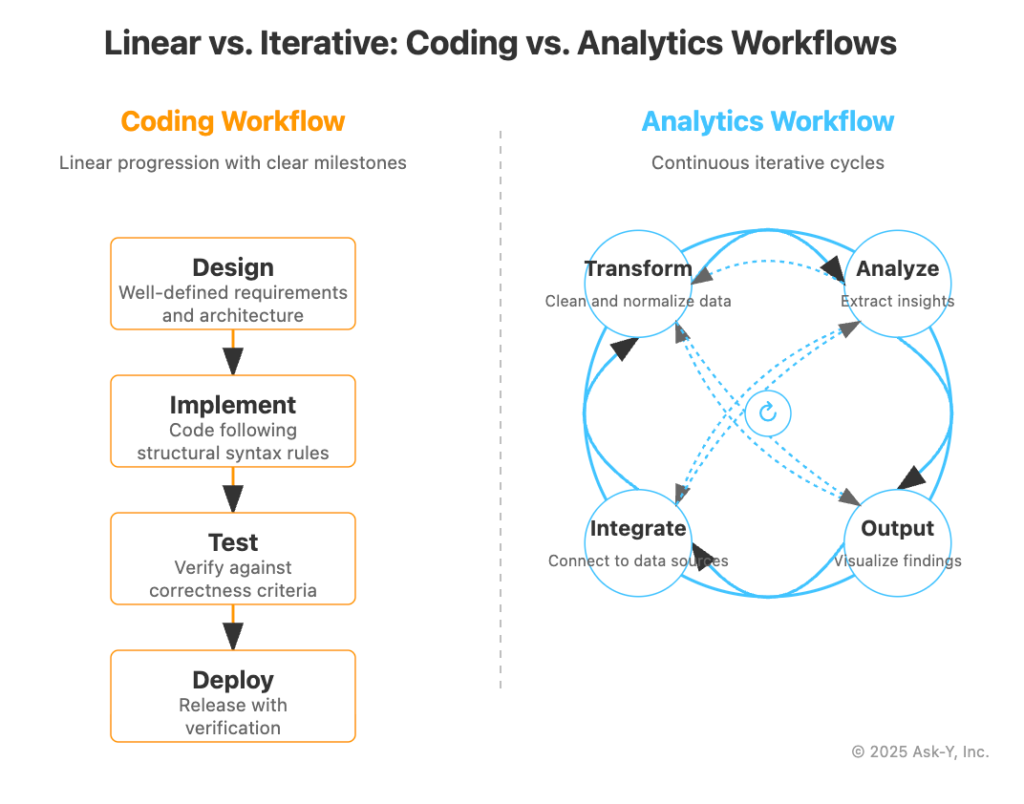
This confusion comes from the converging forces of the race for competitive gains from AI and the complexity of the new world of technologies and skills needed to build the infrastructure to effectively apply LLMs to business needs and gain competitive advantages.
The traditional analytics stack fostered a skillset based segmentation between roles where coding ability was the guardian of the boundaries on the left and business knowledge was the guardian of the boundaries on the right.
Current job postings reveal organizations are confusing the full-stack expansion of the core AI Analyst’s role across the analytics process with the blurring of lines between Analysts and Software Engineers.. This is a “shadow engineering” problem: companies want the productivity and competitiveness gains from LLM driven data analytics fast, confusing building the infrastructure that power analytics with the analytics process itself. This confusion is fueled in part by the importance of Python at every level of the AI stack and in part by the rise of Prompt and Context Engineering as an essential part of both using LLMs and building applications that leverage LLMs..
The Python Paradox
… and how Engineers and Analysts use similar technologies differently
Python’s dominance creates a dangerous illusion. Because analysts and engineers use the same language, organizations assume they need the same skills. But consider:
Analytics Python:
# Business rules embedded
customer_segments = df.groupby(‘account_id’).agg({
‘annual_contract_value’: ‘sum’,
‘renewal_probability’: ‘mean’,
‘executive_sponsor_level’: ‘max’
})
# Apply enterprise pricing tier logic
premium_customers = customer_segments[
(customer_segments[‘annual_contract_value’] > 100000) &
(customer_segments[‘executive_sponsor_level’] >= ‘VP’)
]
Engineering Python:
# Performance optimized
account_metrics = df.groupby(‘account_id’, sort=False).agg({
col_with_high_freq: ‘sum’
})
# Vectorized filtering for speed
high_value_accounts = account_metrics[
(account_metrics[col_with_high_freq] > threshold)
]
Same structure, different worlds. The analyst must understand why VP-level sponsors matter for retention and when $100K triggers enterprise treatment. The engineer just needs the filter to execute efficiently on millions of records.
One requires knowing customer success strategy, the other requires knowing pandas optimization.
In a similar way, the rise of Prompt Engineering as a skill to both interface with LLMs and build applications around LLMs feeds into the confusion between Engineering and Analysts roles. To illustrate how Analysts and Engineers do Prompt Engineering differently let’s look at two prompts written in Ask-Y’s Prism platform using RiffML, our agent framework (more on this here):
Analyst Prompt: This prompts is using the LLM’s capabilities to create view on top of a table
# Overview
Your goal is to write a SQL view and metadata based on the user’s request and the given tables and column schemas.
# Your Task
– Generate SQL code for the new view (valid for PostgreSQL) – it should NOT include the CREATE VIEW statement
….
– Important Rule: Never place DISTINCT after a comma in the SELECT list. DISTINCT must immediately follow SELECT.
….
# Important SQL Guidelines
– Use DISTINCT with subqueries when creating mapping tables
– Always filter out NULL values when creating distinct lists
Engineer Prompt: This prompts is instructing an Agent to perform specific tasks with specific syntax constraints in Prism’s multi-agent framework
You are the Resolver Agent. Your job is to receive all available tables in the project and decide which tables are relevant for the user’s request and for each subsequent phase.
(…)
# Expected Output
– Return a valid XML with a <state> tag containing a JSON object that lists the relevant tables for AddToTable.
– The relevant tables must be listed using their full model reference path, e.g., models/{@sources or mart@}/{@modelname1@}” or “models/{@sources or mart@}/{@modelname2@}.
(…)
– you must NOT escape the model name, just write it as is with a single quote
Again, the same technique with fundamentally a different purpose, requiring different underlying skillsets. The Analysts are structuring data for Analysis and The Engineers is building a framework that will serve the Analysts purpose.
The Future: Divergence, Not Convergence
The current confusion won’t last. As organizations mature in their AI adoption, we’ll see clear differentiation: Engineering will focus on building and maintaining software and Analysts will focus on supporting data driven decision making but the AI Analyst workflow will become dramatically different from the current Data Analyst’s workflow in several ways.
The tools will diverge too. Although the “Cursor for Analytics” analogy isn’t really a directly usable metaphor given the fundamental differences between Software Engineering and Analytics workflows (more on this in our series on What It Takes to Make AI Native Analytics Work In The Real World), there is an emerging set of tools that morph into the Analytics workflow. At Ask-Y, we are building this toolset in the form of a Full Stack AI Analytics Platform (try to say that fast three times in a row…), addressing what we see as the core challenges in making LLMs work for Analytics in the real world across the full analytics cycle.
The Architecture of Understanding: Core Systems Behind AI-Native Analytics
To make LLMs work for Analytics workflows in the real world, we built several specialized components working in concert:

- JAM (Joint Associative Memory) serves as our context-aware memory engine, preserving the rich relationships between data, metrics, and business concepts across organizational boundaries.
- MINGUS (Modeling Intent in Natural Language into Granular, Unambiguous Scripts), interpretative descriptive language that builds a semantic layer between natural language and code
- RiffML, an agent coordination framework that manages the complex, iterative nature of analytics exploration.
- SWING a security framework to manage data access in a paradigm where Analytics Agents access LLMs to perform tasks.
Link to the article on LinkedIn.