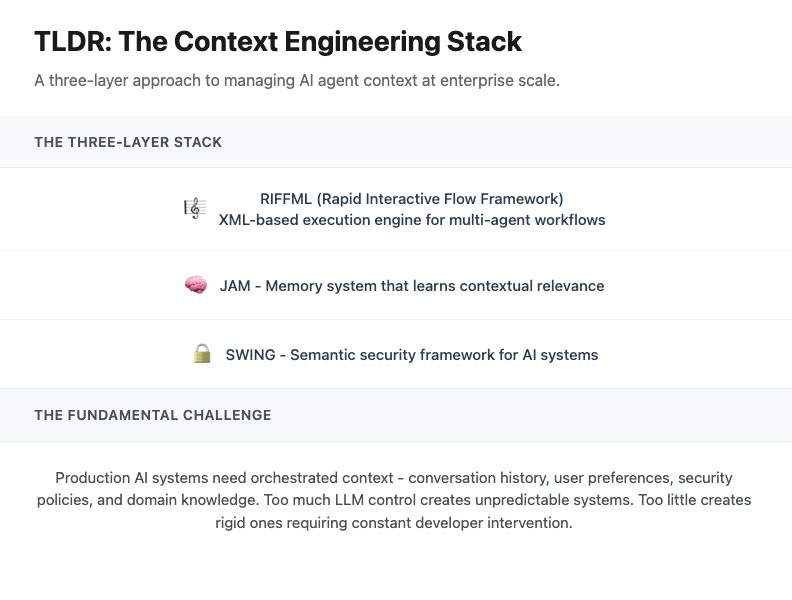
Context engineering has emerged as a critical discipline for production AI systems. While models grow more capable, the challenge isn’t their raw ability – it’s orchestrating the right information, tools, and constraints to make them useful, reliable, and safe. After building AI agents for enterprise analytics, we realized context engineering needs its own dedicated stack. In this paper, we introduce our three-layer stack – RiffML (a control language both experts and LLMs can write), JAM (memory that learns contextual relevance), and SWING (semantic security for AI) – and invite feedback as we consider open sourcing it.
The Fundamental Tension
Teams building AI agents often face this tension. Give the LLM too much control over its context, and you get systems that are slow, expensive, and unpredictable – making dozens of unnecessary tool calls, accessing data they shouldn’t, getting stuck in loops. But try to control everything through prompts or code, and you create a different problem: rigid systems where every context adjustment requires developer intervention.
Leading AI engineering teams from the early days of LLMs in my company Topicx and now at Ask-y, I’ve learned firsthand that orchestrating the right tasks, prompts, and context is crucial to making LLMs effective. However, this challenge becomes especially acute as context requirements grow. Early prototypes work well with simple prompts, but production systems need conversation history, user preferences, security policies, data schemas, learned patterns from past interactions, and domain-specific knowledge. Managing all of this through traditional code becomes unwieldy, while relying on LLMs alone is risky – not reliable or consistent enough for enterprise applications.
The paradox: the people who best understand what context an AI needs – your domain experts, analysts, business users – can’t directly shape the system. Meanwhile, the AI that could dynamically adapt its context lacks the judgment to do so responsibly.
Rethinking Context as a First-Class Citizen
Previously, while designing recommendation engines at Microsoft, I helped build a similar multi-layered stack to manage interactive recommendations while preserving enterprise-grade security. Drawing on those lessons, we built a new three-layer stack that treats context management as a first-class citizen. Each layer addresses a specific challenge:
- RiffML: A declarative language for orchestrating AI workflows that both humans and LLMs can read and write
- JAM: A memory system that learns which context actually helps with which tasks
- SWING: A security framework that enforces data access policies at the context layer
RiffML: A Shared Control Language
RiffML (Reasoning Interactive Flow Framework Markup Language) is our answer to the control paradox. It’s an XML-based orchestration language designed specifically for AI agents. Why XML? Because it’s one of the few formats that both humans (that struggle with more effecient formats like yaml or json) and LLMs can reliably parse and generate.
Here’s what makes it different:
<riff name="DataAnalysis">
<phase name="understand_request">
<!-- Persistent instructions across all LLM calls -->
<instruct history="core">
You help users analyze data. Available tables: ${project.catalog.models}
</instruct>
<!-- Conditional context based on user permissions -->
<instruct history="financial" security="read:financial.detailed">
You can access detailed margin data and customer-level information.
</instruct>
<!-- Wait for input, adding it to specific history stream -->
<wait history="user_queries"/>
<!-- Call LLM with selective context -->
<llm history="core,user_queries" storeTarget="session.analysis_plan"/>
<!-- Dynamic flow control -->
<if condition="session.analysis_plan.requires_financial_data">
<next phase="validate_financial_access"/>
</if>
</phase>
</riff> This isn’t just a templating language or a no-code solution for writing prompts. It’s a control plane that sits between human expertise and AI capability. From my experience developing chatbots at Topicx and expert systems at Vitalerter, one of the first lessons you learn is the importance of investing in robust editors and expert tools. Experts can write phases that encode business logic, while LLMs can generate phases to handle novel situations. The engine enforces boundaries on both.
Agents Writing Agents
The real power emerges when LLMs can generate their own multi-agent flows and context management logic dynamically. This was a key requirement for us, as we realized that over time, LLMs would be able do it much better than human coders or experts, but we also recognized the need of strict controls and a way to fallback and balance this with expert prompts. Existing multi-agent platforms that we tested like AutoGen and LangGraph lacked this core capability – agent and context logic is based on (mostly python) code, so adding agents or setting agent logic requires manual programming. It’s not safe or practical to let an LLM directly write or modify product code, so we needed an approach that let LLMs operate safely and flexibly at the orchestration layer. This is how it works:
<phase name="complex_analysis">
<instruct>
The user needs a multi-step analysis. Generate a workflow that:
1. Identifies required data sources
2. Validates access permissions
3. Executes the analysis in stages
4. Handles common failure modes
<expect>
Write instructions for an AI agent in xml language with the following tag: ...
</expect>
</instruct>
<!-- LLM generates and executes its own workflow -->
<llm executeRiff="true"/>
</phase> The magic of executeRiff=”true” is that agents don’t just process instructions—they write new RiffML to define their own workflows. When an agent realizes it needs different context or hits a limitation, it can create new phases, spawn specialized agents, or reorganize its approach.
But here’s the key: when the AI-generated approach doesn’t work—when it loops, makes poor decisions, or violates policies – the RiffML engine is stopping or limiting the execution, and experts can write fallback phases that guide the system back on track. It’s not all-or-nothing automation; it’s collaborative orchestration.
<!-- Expert can provide fallback for common failure patterns -->
<phase name="analysis_timeout">
<message>Analysis is taking longer than expected. Let me try a focused approach.</message>
<instruct history="essential_only">Focus only on the specific question asked</instruct>
<llm history="minimal_context"/>
</phase> This creates a new operating model: experts write high-level phases capturing business intent, LLMs generate detailed implementation, and the system enforces guardrails throughout.
Security Through Semantic Control
Allowing LLMs to write and execute code is extremely powerful but equally risky. SWING (Security, Workspaces, Identity, Nesting and Grouping) provides semantic security at the context layer to control, limit and audit the execution environment:
<!-- Tool execution respects user permissions -->
<RunTool tool="query_database"
security="read:data.sales.aggregated"
input="session.query">
SELECT region, SUM(revenue) FROM sales GROUP BY region
</RunTool>
<!-- State access enforces data classification -->
<state name="project.customer_data"
security="resource:data.sensitive,org:sales.us">
${load_customer_segments()}
</state> Every piece of context – data, tools, memories – carries semantic tags. Permissions aren’t binary; they’re tag-based rules like “read medium-sensitivity BigQuery data from US finance org.” This allows security policies to evolve with your data taxonomy while maintaining strict control over what each agent can access.
Learning What Context Matters
Static context rules don’t scale. JAM (Joint Associative Memory) learns from experience which context actually helps with which tasks.
Traditional RAG systems treat retrieval as a ranking problem: find the most similar documents and include them. JAM instead tracks outcomes: when specific context leads to successful task completion, it strengthens those associations. Over time, it builds generalizations:
<memory topic="financial_compliance_queries">
For compliance analysis, users typically need:
- Current regulatory framework (SOX, GDPR)
- Recent audit findings
- Historical violation patterns
Exclude: marketing data, product roadmaps
</memory> These learned patterns become reusable context streams. The system doesn’t just remember facts—it learns which facts matter for which purposes.
Why This Architecture Matters
This approach changes several dynamics:
For Domain Experts: They can directly encode their knowledge without writing code. A financial analyst can define exactly what context matters for compliance queries. A data scientist can specify how models should be validated.
For Engineering Teams: The focus shifts from managing conversation flows to building capabilities. Instead of writing boilerplate for state management and context injection, engineers create tools and integrations that experts and agents can orchestrate.
For Enterprises: Every decision is auditable. Every data access is controlled. The system provides the flexibility of AI with the governance of traditional software.
Open Questions for the Community
We built this stack for our specific needs, but the patterns feel broadly applicable. If you’re building production AI systems, we’re curious about your experience:
- How do you balance AI autonomy with control requirements?
- What tools do you use for context management beyond basic RAG?
- How do you enable non-technical stakeholders to shape AI behavior?
- What would an ideal context engineering platform provide?
We’re considering open-sourcing parts of this stack—not because we think it’s the definitive solution, but because context engineering needs more shared patterns and tools. The challenges we faced aren’t unique, but the solutions are still emerging.
Some specific areas where we’d love to exchange notes:
- Declarative orchestration: Is XML the right choice? What alternatives might work better?
- Memory generalization: How else might systems learn which context matters?
- Security models: What frameworks work for your compliance requirements?
We’re actively looking for teams facing similar challenges to exchange ideas and potentially collaborate on open-source tooling. If you’re building production AI systems and care about context management, reach out. Let’s figure out what the next generation of context engineering tools should look like.
Link to the article on LinkedIn.