
MeasureCamp NYC 2026 — Recap and Reflections
I gave a talk at MeasureCamp NYC last week. The title was “Specs, Not Vibes” and the subtitle told the real story: What Can Digital Analysts Learn from the Agent Revolution in Software Engineering.
MeasureCamp is an unconference — people vote with their feet. You pitch your session on a board, and a professional audience of analysts, data engineers, and marketing product people decide whether your topic is worth their next 20 minutes. I wasn’t sure a software engineer talking about agent workflows would draw a crowd. It did. And the conversation that followed was one of the most interesting I’ve had this year.
Here’s what I presented, what I learned, and why I think the gap between engineering and analytics is about to close fast.
The State of Things
Let me set the stage with numbers that are already outdated by the time you read this.
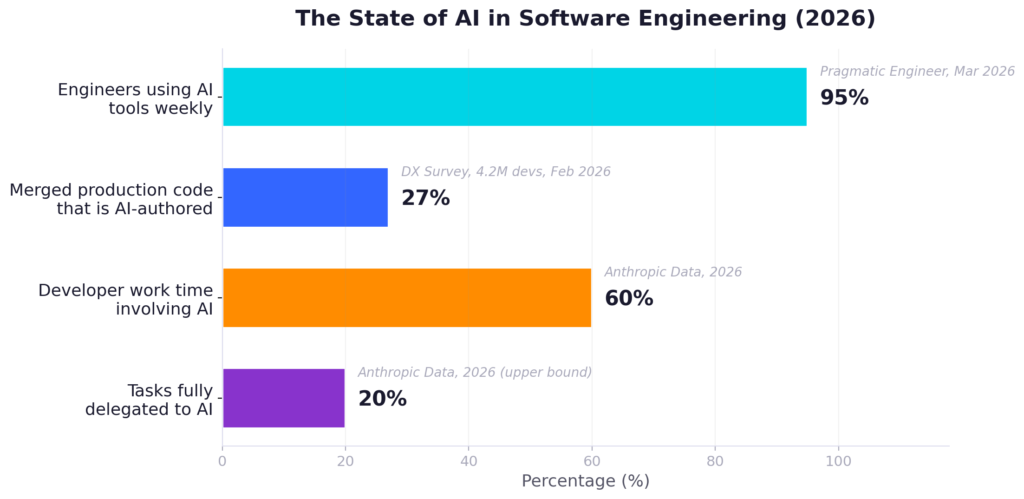
95% of engineers now use AI tools weekly (Pragmatic Engineer, March 2026). 27% of merged production code is AI-authored across 4.2 million developers surveyed by DX in February 2026. For my engineering team at Ask-y, it’s closer to 100%. We research with AI. We mock UIs with AI. Our product managers and even the CEO now write spike apps with AI. We communicate in AI artifacts — sending each other specs and prototypes that were generated, reviewed, and iterated with agents. (This has been part of our culture from the start — see our earlier piece, AI Native Analytics: What It Takes to Work in the Real World.)
Claude Code was the inflection point. When Anthropic released Opus 4.6 just 2 months ago, it changed everything. Before that, we used Windsurf and Cursor and did far more manual merging, constantly fighting the tools’ inability to handle complex, multi-file context. Claude Code can actually research a codebase, understand architectural decisions, and write code that respects the existing patterns. And there was zero stickiness – we migrated the entire team in two days, no hitch. That single capability shift let me transition from writing code to writing specs.
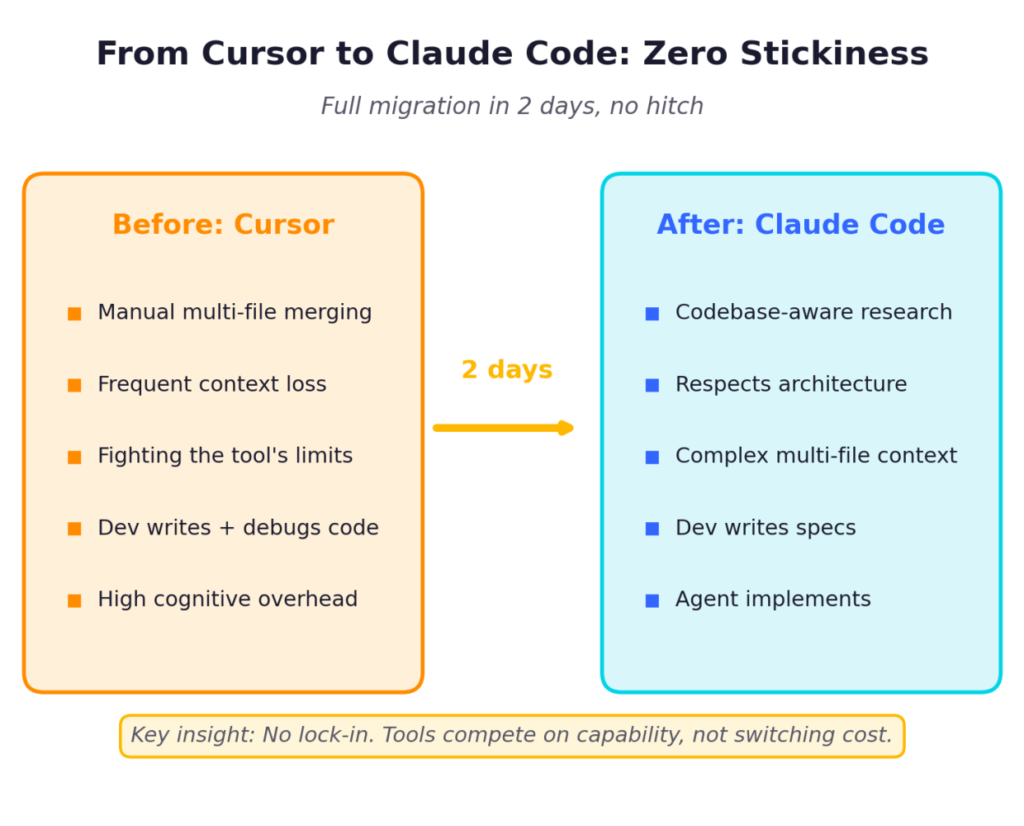
But here’s the part that matters: without discipline, none of this works.
Here’s the twist that should make every manager pause: METR measured experienced developers using AI and found they actually got 19% slower — while genuinely believing they were 20% faster. The productivity was a mirage. That matched our early experience exactly. You feel productive because the AI is generating stuff. But you’re debugging its output for hours. Or worse — you don’t debug it, and the bug ships.
We hit $1,500 per developer per month in LLM tokens before we developed a methodology. That’s well above the typical enterprise budget – most teams report $200–$500 per developer per month on LLM APIs, and 68% of enterprises underestimate their first-year AI spend by more than 3x. The agents would research code they should already know, burn attention on the wrong context, write worse and duplicated code as a result – and we’d pay for every wasted token. Discipline isn’t just about quality. It’s about economics and scale.
The Structural Problems — AI without discipline fails invisibly.
These are not bugs in the current model generation. They’re architectural constraints that will persist, and you need to design around them. These constraints are baked into the transformer architecture itself, with no successor paradigm currently in sight. Until we move beyond attention-based models, these trade-offs are the physics of AI-assisted work.
Context window degradation is the most misunderstood. People think a 200K token window means you can dump 200K tokens of context and get great output. The opposite is true. More input means less attention per token, which means worse output. I experience this daily — I’m editing a presentation with Claude, ask it to fix something, and it uses the wrong version of a slide because with longer context it loses focus on what’s recent. More is literally less.

When tasks get complex enough, the framework auto-compacts your conversation by summarizing earlier parts. Those summaries drop details from your spec. I once asked Claude why it ignored a specific instruction, and it told me it had “decided” that part wasn’t important enough to keep. It made that decision during compaction – silently, without telling me.
A practical example: I paste long server logs with exception traces. If I put them directly into the conversation, Claude focuses on the wrong errors — the noisy ones, not the meaningful ones. But if I save those logs to a file and let Claude search and reason over them with its tools, it uses context far more effectively. Same data, different context management, dramatically different results.
Training set gravity is subtle and dangerous. I had a spec asking Claude to use a custom alert component in a UI. Multiple times, across multiple attempts, it generated the default JavaScript alert() instead. I clarified the instructions. I repeated them. I made them more prominent. It kept defaulting. What I eventually realized is that when there’s ambiguity and cognitive load, the model falls back to its training distribution. The lesson: how you name things and frame instructions directly determines whether the agent follows your spec or its training data.
Self-validation loops are where things get expensive. You give Claude a specification, it implements something — maybe only part of the spec, maybe a slightly different interpretation — and then you ask it to test itself. It creates a test suite that validates its own assumptions, tells you everything passes, and you move on. This is exactly why software engineering learned decades ago that developers shouldn’t test their own code. The same principle applies to agents, possibly more so. Anthropic’s own engineering team confirmed this in their harness design research (March 2026): “agents reliably skew positive when grading their own work.” Their solution: a strict separation between generator and evaluator agents.
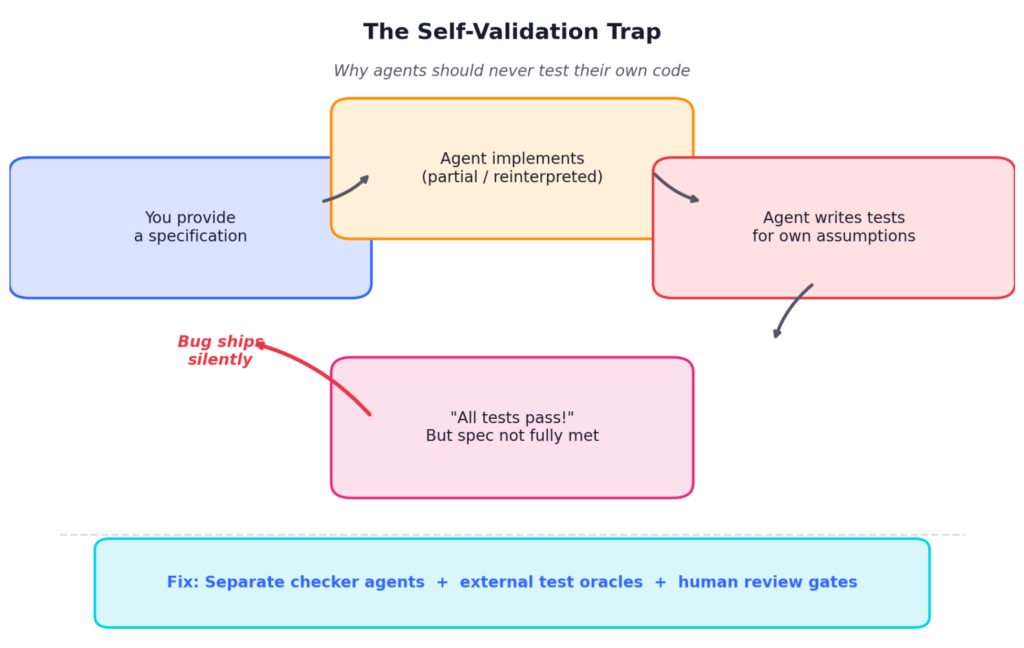
Memory is an illusion. Claude has memory files that persist instructions across sessions. In practice, these are followed roughly 50% of the time. Your documentation IS the agent’s RAM. If you don’t maintain it, the agent starts every session essentially blank or worst – dirty.
The real danger across all of these: the failures don’t crash. They produce plausible, well-formatted, confidently presented wrong output. These are the expensive failures — the ones that look like they work. What’s Working: Key Patterns
What’s Working: Key Patterns
Three patterns have emerged from the engineering community that fundamentally changed how I work.
Spec-Driven Development is the most important shift. The spec is the product. Code is a side effect. GitHub’s spec-kit, Anthropic’s tooling, and several community frameworks all converge on the same structure: Requirements, Design, Tasks, Implementation — with review gates between each phase.
For my team, this means the specification document becomes the source of truth. We check specs into version control alongside code. They represent the system more accurately than the implementation, because the implementation can be regenerated but the intent lives in the spec.
Strategic decomposition is what makes specs executable. The principle is simple: break work into units that fit one effective context window. Each unit gets the general direction plus exactly the context it needs — no more, no less.
I think of it like managing a large organization. You set strategy and direction. Each department handles only its part. The decomposition skill is knowing the boundary. And you develop it by experimenting: you give the agent a task, see where it struggles, and learn where to split next time.
TDD and validation gates close the loop. Tests are an external oracle that stays accurate regardless of how polluted the session gets. Separate checker agents — running in a different context, with different assumptions — break the self-validation loop.
In practice, I configure hooks that enforce deterministic validation before the agent says ’done’. Typecheck, lint, test — if any fail, the commit is blocked. The agent must self-correct. The agent hasn’t replaced my engineering judgment. It’s replaced the typing.
For analysts, the translation is direct: think of these as automated data-quality checks that run before any dashboard goes live. At Ask-y, we’re building exactly this kind of automated backpressure into our agent framework for analytics workflows.
The Orchestrator’s Workflow
Here’s how an actual multi-day project works for me now:
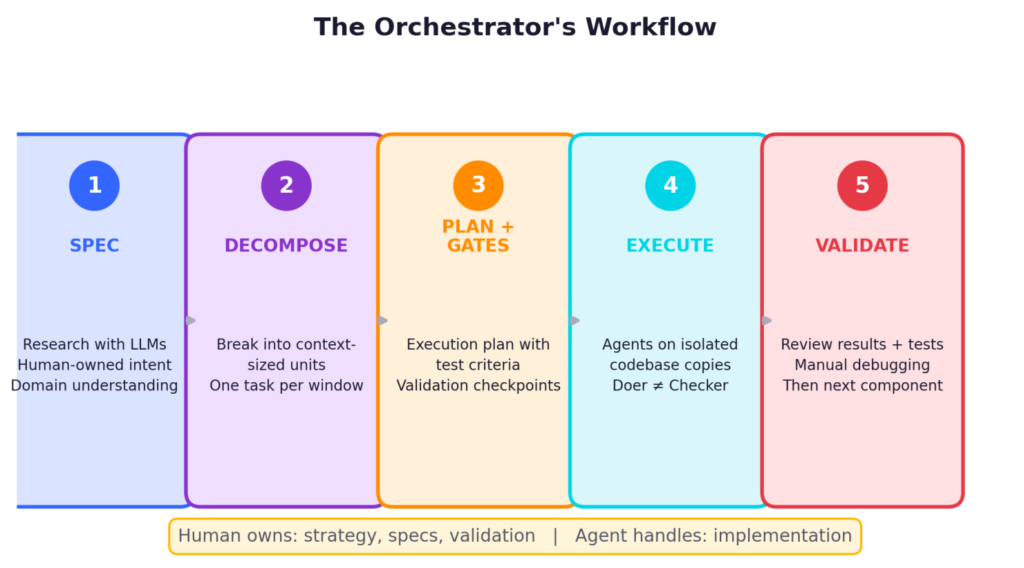
- Spec – I research with LLMs. Review architectures, test ideas, read about patterns. But the spec is human-owned. I decide what goes in.
- Decompose – I break the spec into components small enough that each can be completed within one agent context window without degradation.
- Plan with gates – I write an execution plan with a separate test criteria document. Each phase has validation checkpoints.
- Execute – Agents run on isolated copies of the codebase. Separate agents handle implementation and testing — the doer is never the checker.
- Validate – I review results and tests after each component. Manual debugging of key code paths. Only after I have confidence do I move to the next.
Anthropic published a striking cost comparison: a solo agent building a game maker spent 20 minutes and $9 — and produced broken core functionality. The same task through a proper harness took 6 hours and $200 — and actually worked. (Harness Design for Long-Running Apps, Anthropic Engineering, March 2026.)
What This Could Mean for Analytics
Spec-driven analytics: If nobody writes a spec, what does the AI work from? Matt Stockton described a workflow where you transcribe a stakeholder call, feed it to Claude, and let exploration reveal the actual requirements. The call recording might be your spec.
Decomposition and scope: A 20-chart dashboard in one prompt produces garbage. One metric, one data source, one question per agent session. Build up from there.
The semantic layer as test suite: dbt Labs found 83% accuracy when AI had semantic context versus roughly 25% on raw tables. Without a semantic layer, natural language querying is a hallucination machine with convincing formatting.
Bridging domain memory: An experienced analyst carries years of institutional context. An LLM starts fresh every session. You have to actively maintain the context that makes AI useful. It doesn’t learn it on its own.
What I Saw at MeasureCamp
The event was excellent. But the most interesting thing was seeing where analysts actually are with AI adoption. The landscape is shifting — some companies are restructuring teams around AI workflows. Others are cautious, especially in regulated industries.
One exchange captured the core tension perfectly. A participant from a large financial institution described going “full steam ahead” with AI — but acknowledged it would be “the wild west.” Another referenced Nassim Taleb’s Antifragile, questioning systemic risk. The organizations that build discipline — specs, validation, governance — will be far better positioned than those that discover the need after a production failure.
The Takeaway
The lesson from software engineering’s agent revolution isn’t “use more AI.” It’s that AI without discipline fails invisibly.
The teams that will thrive won’t be the ones with the best models. They’ll be the ones with the best specs, the most rigorous validation, and the discipline to not trust the machine’s confidence.
The tooling landscape is becoming composable rather than monolithic — OpenAI shipped a Codex plugin for Claude Code, and cross-agent orchestration is quickly becoming the default. Meanwhile, late-night Codex tasks started around 11pm are 60% more likely to run 3+ hours — engineers are delegating to background agents overnight. The “orchestrator” is becoming a 24-hour operation.
The core principle won’t change: humans own the strategy, the specifications, and the validation. Agents handle the implementation. The discipline gap between those two roles is where the real competitive advantage lives.
—
Avigad Oron, Head of Technology
Link to the article on LinkedIn.