By Katrin Ribant (CEO), Avigad Oron (Head of Technology) and Yuval Bork (Product Manager)
In this first article in our Prompting Context Engineering for Analytics series, we are sharing learnings from our experience building a multi-agent Analytics platform and exploring how AI Analysts can use Prompt Engineering and Context Engineering for their projects.
If you’re an AI Analyst, you’ve hit this wall: your prompts work for some queries but not others, you got stuck in loops, you try to guide the LLM through an analytical process and somewhere between the third and fourth step it loses the plot and you only realize it a few steps down the line… and you end up spending more time trying to get the LLM back on track than you would have spent doing the analysis manually…
All these issues can be helped with better prompting and context engineering.
This series explores prompt and context engineering specifically for analytics workflows: how to structure prompts that preserve statistical reasoning, manage multi-step analytical context, and ensure AI agents maintain the domain expertise that makes analysis valuable rather than just fast. We’ll start with advanced prompting techniques you can use immediately, then progress to sophisticated frameworks that handle the complex, branching logic that real analytical work demands.
The Context Engineering Challenge Every AI Analyst Faces
As an AI Analyst, you’ve experienced this countless times: you write what seems like a perfectly clear prompt, and the AI gives you results that are just not what you need. You then try to get the AI to correct itself and use the right variable, or change the computation to what it should be and you end up stuck in a loop.
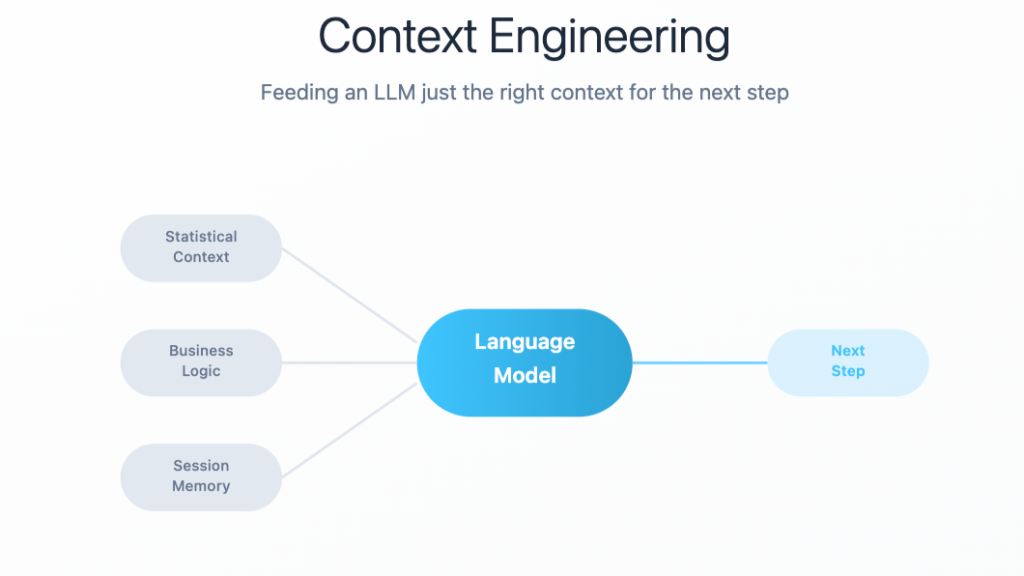
Context engineering is “the challenge of feeding an LLM just the right context for the next step” *. This challenge becomes especially acute when working with multi-step analytical workflows. Each AI Analyst has their own threshold in managing the challenge of balancing the work needed to build effective prompts for complex workflows and balancing the short and long term gains of manual work versus leveraging LLM to extend one’s analytical abilities and efficiency. But ultimately “Everything is context engineering (…) To get the best outputs, you need to give them the best inputs.”.**
*: If you haven’t listened to Lance Martin on Latent Space’s episode “Context Engineering for Agents” , here is the link (https://www.youtube.com/watch?v=_IlTcWciEC4)
**: This sentence is in the intro of Factor 3 of the excellent “12-Factor Agents” by Dex Horthy from Humalayer, here https://github.com/humanlayer/12-factor-agents/tree/main
Why Analytics Prompting Is Different
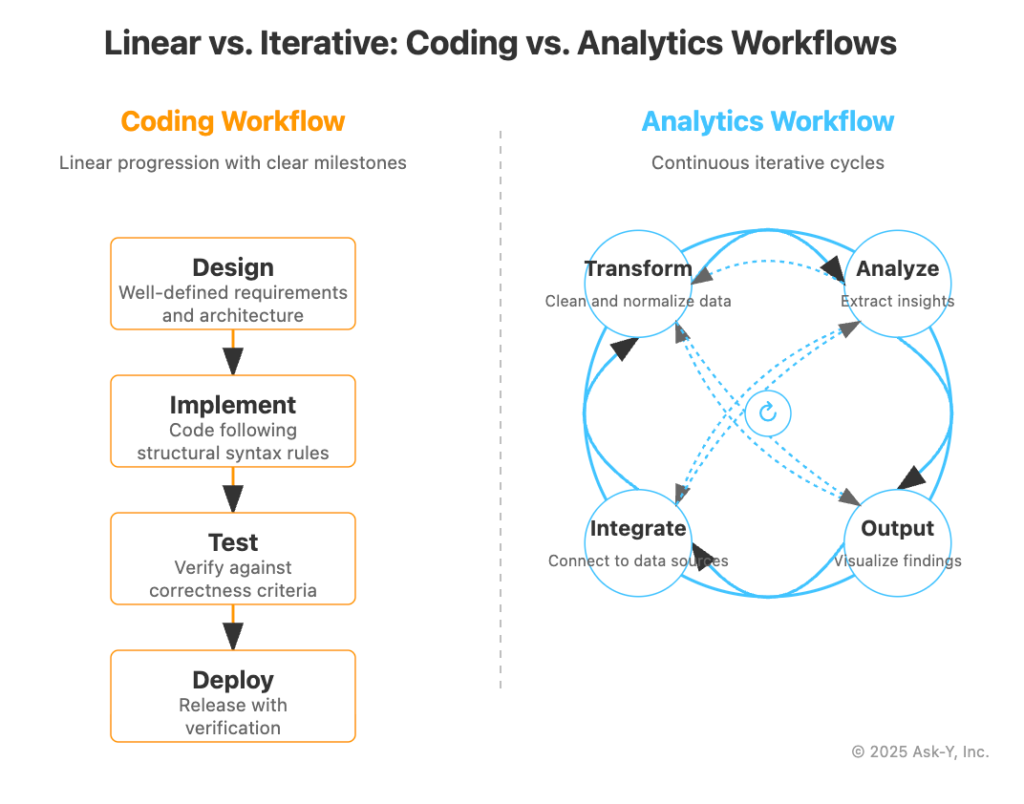
Unlike Coding workflows, which are mostly linear and have objective success criteria
analytical workflows are circular in nature and have outcomes that tend to lead to more questions (read this form a more detailed discussion on coding vs analytics workflows https://www.linkedin.com/pulse/from-code-context-building-ai-thinks-like-analyst-coder-katrin-ribant-q1rze/).
Prompting and Context Engineering for analytics faces specific challenges that are very different from the ones faced by software engineers: software engineers benefit from IDE’s that deduce context from their project file structure, for analysts understanding data structure between different data sources and resolving business entities to data fields is largely up to the individual analyst gathering context from the data owners and business stakeholders.
This isn’t just a technical problem – it’s a fundamental challenge in how you communicate analytical tasks to LLMs.
How Analytics Prompting Is Different
As an AI Analyst, you need different prompting strategies than software developers or content creators. Your prompts must handle:
Business Translation & Domain Intelligence: Your prompts must bridge two languages – business questions and analytical implementation. Include industry terminology, semantic layer definitions, and business logic constraints. The AI needs to understand not just what metric to calculate, but why it matters and how it connects to business outcomes.
Example prompt for ecommerce analysis:

Transparent Analytical Reasoning: Every analytical choice should be explainable and modifiable. Generate clear, readable code that other analysts can understand and adjust, where each step is clearly distinct and the logic between steps is easy to follow. Build prompts that not only solve the current question but suggest logical next steps, keeping the analytical pathway and each decision along the way transparent and modifiable.
Example prompt structure:

Immediate Presentation Standards: Unlike code that runs behind the scenes, your analytical outputs are immediately visible to yourself and your stakeholders. Design prompts that prioritize clean, intuitive presentations – meaningful column names, logical ordering, and formatting that tells a story at first glance.
Example formatting requirements:

Built-in Validation & Trust: Analytics demands higher accuracy standards than most AI applications. Structure prompts to include confidence assessments, data quality checks, and assumption validation. Every analytical output should come with its own credibility assessment.
Example validation prompt:

This makes context injection into prompts a particularly hard challenge in analytics.
The main issue is to combine
- prompt engineering techniques that are efficient enough to not end up taking more time than doing the task manually
with
- enough experience about the chosen AI model to know which model is the most likely to give a fast and correct answer for any particular step in an analytics project.
Building Your Analytics Prompting System
Rather than reinventing prompts each time, build a systematic approach to prompt management:
Organize Your Prompt Library: Create a structured folder system with clear naming conventions. Keep a master “Analytics_Prompting_Guide.txt” file that you can upload to AI projects, containing your standard analytical frameworks, business context definitions, and output formatting requirements. This becomes your prompt template that instructs the AI how to write domain-specific prompts for you.
Create Analytical Archetypes: Develop standardized prompt templates for common analytics scenarios – “Cohort Analysis Template,” “A/B Test Evaluation Template,” “Marketing Attribution Template.” Each template includes pre-built business context, validation requirements, and output formatting. This ensures consistency across your team and reduces setup time for recurring analyses.
Modular Prompt Components: Build reusable prompt modules that can be mixed and matched – a “Data Quality Check Module,” “Business Context Module,” “Visualization Requirements Module.” Combine these building blocks based on your specific analytical needs, creating custom prompts from proven components.
⇒ If you are really into data , you can do Prompt Performance Tracking: Log which prompts produced actionable insights versus which requires extensive revision. Track metrics like “time to usable output” and “stakeholder satisfaction” to identify your most effective prompting patterns. Then analyze those metrics and create a dashboard that will show you Prompts performance… no i am taking this too far 🙂 …
Staged Prompting Workflows: Design multi-stage prompt sequences for complex analyses
Stage 1: Data exploration and quality assessment
Stage 2: Core analysis
Stage 3: Business insight generation
Each stage feeds refined context to the next, creating a systematic analytical pipeline.
Use Prompt Management Tools: Consider platforms like Prompt Layer or similar prompt libraries that offer version tracking, variable substitution, and model selection. These tools enable prompt versioning, A/B testing different prompt approaches and chaining multiple prompts together – crucial for complex analytical workflows that require multiple steps.
Essential Analytics Prompting Principles:
- Separate Instructions from Outputs: Structure your prompts clearly with distinct sections. Avoid mixing instructions with expected outputs.
Instead of:
- “Calculate conversion rates. Show me a table. Then find outliers. Display them in a chart.”
Do this:
- “INSTRUCTIONS: Calculate conversion rates and identify statistical outliers
- EXPECTED OUTPUT: (1) Summary table with conversion rates by channel (2) Visualization highlighting outliers with explanations”
- One Analytical Task Per Prompt: Don’t merge unrelated analyses. Keep “customer segmentation” separate from “channel performance” – even if you plan to combine insights later. This maintains clarity and makes debugging easier.
- Context Selection Strategy: Include only relevant context for each specific task. If you need broader context, use an initial prompt to filter down to what’s relevant, then pass that focused context to your main analytical prompt.
Scenario: You need to analyze Q4 email campaign performance, but your dataset contains 18 months of multi-channel marketing data with dozens of campaigns across email, social, paid search, and display advertising.
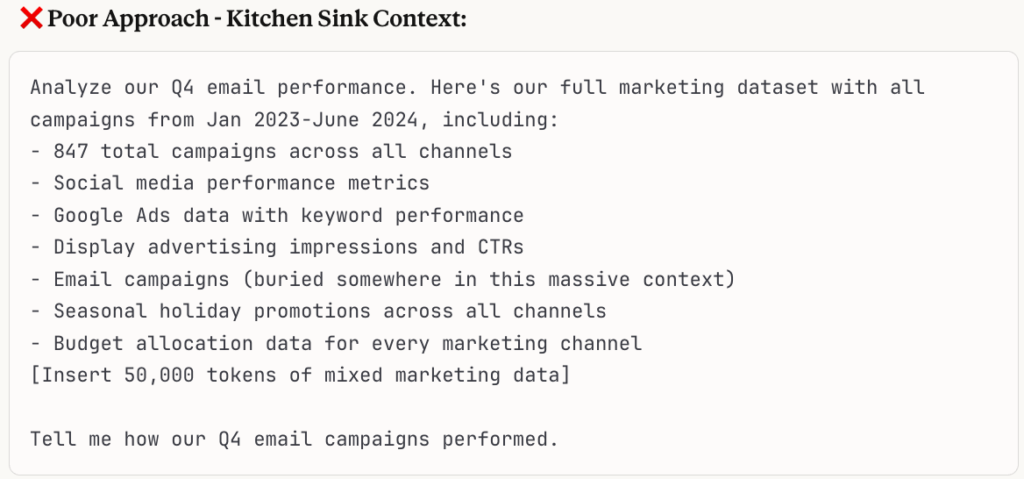

Result: The AI gets precisely the context it needs without being overwhelmed by irrelevant data, leading to faster, more accurate analysis focused on your actual question.
This two-stage approach is especially valuable when working with large datasets, complex business contexts, or when you need to analyze specific segments within broader data collections.
- Distinguish Internal vs External Outputs: Clearly specify what’s for your internal analysis notes versus what gets presented to stakeholders. Make explicit whether the output should be “analyst working notes” or “executive summary format.”
- Model Selection Strategy: Start with the fastest, most cost-effective model for initial exploration. If results don’t meet your analytical standards, upgrade to more sophisticated models for complex reasoning. Think of it as a pipeline: quick models for data exploration, advanced models for statistical inference and business recommendations.
The goal is creating a prompting system that enhances rather than hinders your analytical workflow – making AI a true analytical partner rather than another tool that requires more time to manage than the analysis itself.
Methods to Reduce LLM Hallucinations in Analytics
Analytics work demands exceptional accuracy – no one needs approximative insights on data that may or may not not be complete and accurate.
Here are some methods we use to minimize AI hallucinations:
Constraint-Based Prompting: Explicit Boundary Setting: Define clear constraints in your prompts. Instead of “analyze customer behavior,” specify “analyze only customers with >3 orders in the past 6 months, using data from our CRM system dated 2024-Q4.” This prevents the AI from inventing customer segments or data points that don’t exist in your actual dataset.
Data Source Validation: Specify your exact data sources and have the AI acknowledge them. “Using only the sales_data table from our warehouse, where order_date is between 2024-10-01 and 2024-12-31…” This anchors the analysis to real data rather than allowing the AI to fill gaps with plausible but fictional information.
Validation Checkpoints: Include expected data volume checks in your prompts to catch potential issues early. “From 2024-10-01 to 2024-12-31, I expect approximately 300 rows from the sales_data table. Please confirm the actual row count before proceeding with analysis.” This helps identify data availability issues or query problems before investing in detailed analytical work. This can also be applied to expected value ranges etc.
Make Failure an Option: The LLM wants to please you, giving it an option to fail makes it less like it will make up data points. You can add options like: if you don’t know/don’t find the data for the computation, input value N/A. This way failure becomes part of the acceptable answer set.
Verification Workflows: Create a separate prompt with verification steps, including the verification steps within your main analytical prompts can confuse the LLM and distract it from the main task. First, execute your primary analysis: “Calculate the conversion rate for Q4 2024 customers.” Then, run a separate validation prompt: “Using the same dataset, verify that total transactions equals the sum of successful orders. Report any discrepancies and calculate the difference.” This approach keeps each prompt focused on a single objective while ensuring analytical accuracy through dedicated verification steps.
Sanity Check Integration: Similarly, implement business logic checks through separate validation prompts. First, complete your main analysis: “Calculate month-over-month growth rates for all key metrics in Q4 2024.” Then, run an independent sanity check: “Review these calculated growth rates against our historical baseline of 25% maximum monthly growth. Flag any metrics exceeding this threshold for manual review.” This separation ensures more reliable validation since the LLM approaches the data with fresh perspective rather than defending its previous calculations.
The PRISM Framework for Analytics Context Engineering
The PRISM framework provides a systematic approach to crafting prompts that deliver reliable, actionable analytical insights while maintaining the rigor your stakeholders expect. We used this framework to build the multi-agent framework of Prism, our AI Analytics platform. This framework has over 1000 prompts managing a variety of specialized analytics agents. Here are the basic principles of prompting with the PRISM framework:
PRISM Framework
- Position (Role Definition – Be Analytically Specific)
- Requirements (Task Specification – Include Success Criteria)
- Intelligence (Context Management – Curate Analytical Relevance)
- Scenarios (Scenario Planning – Handle Analytical Failures)
- Materialization (Output Structure – Enable Both Analysis and Communication)
This structured approach ensures every analytical prompt contains the context, constraints, and quality controls necessary for production-ready analysis.
Step 1: Role Definition – Be Analytically Specific
Define both the AI’s expertise and who it’s serving to create the right analytical context:
Weak: “You are a data analyst.”
Strong: “You are a senior data analyst with 10+ years experience in ecommerce analytics, specializing in customer behavior analysis and marketing attribution modeling. You are helping a marketing analyst at a mid-size ecommerce company who needs to optimize channel performance and budget allocation.”
Even Better: “You are a senior data analyst with expertise in statistical analysis and customer segmentation. You’re assisting a marketing analyst at a B2C ecommerce company who has solid Excel skills but limited SQL experience. They need analysis that translates complex data patterns into actionable marketing strategies for their CMO.”
The key is encoding both the analytical expertise AND the recipient context. This dual definition helps the AI understand:
- What analytical methods to use (senior-level statistical approaches)
- How to communicate findings (accessible to someone with Excel but not SQL skills)
- What business context matters (ecommerce marketing optimization)
- What level of detail to provide (strategic insights for CMO presentation)
This persona pairing ensures your AI delivers analysis that matches both the sophistication your data requires and the communication style your audience needs.
Step 2: Task Specification – Include Success Criteria Transform vague requests into analytically precise objectives with clear dos and don’ts: What TO Do:
- Define specific deliverables: “Identify 3-5 customer segments” not “find segments”
- Include statistical requirements: “95% confidence level, minimum 100 customers per segment”
- Specify business constraints: “segments must be actionable for email marketing campaigns”
- Set validation standards: “validate using holdout data or cross-validation methods”
- Define success metrics: “segments should show >20% difference in purchase behavior”
- Provide concrete examples: Include examples of good vs. bad segments to clarify expectations. “Good segment example: ‘High-value mobile users who purchase premium products monthly.’ Bad segment example: ‘Customers who sometimes buy things’ – too vague for actionable marketing.” This adds an essential layer of explanation that users often forget to define explicitly, helping the AI understand the quality and specificity you expect.
What NOT To Do:
- Avoid vague requests: “Analyze customer data and find insights”
- Don’t skip sample size requirements: “Find customer groups” (without minimum viable segment size)
- Never omit business context: “Create segments” (without explaining how they’ll be used)
- Don’t forget validation: “Show me patterns” (without requiring statistical testing)
Example Transformation:
Weak: “Analyze customer data and find segments.”
Strong: “Identify 3-5 customer segments using the following criteria:
- Statistical: 95% confidence level, minimum 100 customers per segment
- Business: Segments must differ by >20% in average order value or purchase frequency
- Actionable: Each segment needs distinct characteristics for targeted email campaigns
- Validation: Test segment stability using 70/30 train/validation split
- Output: Provide segment profiles with key differentiating behaviors and recommended marketing actions”
Your prompt should specify not just what to deliver and what not to deliver, but also exactly what makes that deliverable analytically sound and business-ready.
Step 3: Context Management – Curate Analytical Relevance
This isn’t about including everything – it’s about systematic context curation:
Statistical Context: “Historical analyses show seasonal patterns with 15-20% variance in Q4. Previous segmentation identified issues with high-value/low-frequency customers requiring separate treatment.”
Business Context: “Marketing team requires segments actionable for email campaigns (minimum 1000 customers) and must comply with GDPR consent requirements. Previous segments performed best when based on purchase behavior rather than demographics.”
Technical Context: “Data quality: Customer table has 94% completeness for behavioral fields, 78% for demographic. Transaction history complete for 18 months. Known data quality issue: duplicate customers across regions.”
Step 4: Scenario Planning – Handle Analytical Failures
Analytics fails differently than other AI tasks. Your prompts must anticipate analytical failure modes:
Statistical Failures: “If assumption testing reveals non-normal distributions, switch to non-parametric methods and document the decision.”
Data Quality Issues: “If missing data exceeds 20% for any key variable, flag for human review before proceeding with imputation.”
Business Logic Violations: “If segments don’t meet minimum size requirements, document why and propose alternative approaches. Don’t make up segments.”
Regulatory Conflicts: “If analysis suggests approaches that conflict with privacy requirements, stop analysis and flag for human review.”
Step 5: Output Structure – Enable Both Analysis and Communication Specify exact formats with concrete structure requirements and examples:
What TO Do:
- Use structured formats: JSON, tables, numbered lists with specific dimensions
- Define exact requirements: “table with 6 columns” not “show results in a table”
- Provide output examples so the AI understands your exact expectations
- Specify data types and formatting: percentages vs decimals, date formats, rounding rules
- Include both analytical detail and executive-ready summaries
Request process reflection: Ask the LLM to document analytical decisions and challenges encountered. “Include a methodology notes section explaining any data quality issues, non-normal distributions encountered, and how these factors influenced your analytical approach and results.”
What NOT To Do:
- Vague format requests: “Present findings clearly”
- Skip structural specifications: “Show segments” (without defining how)
- Omit example outputs: “Create a summary” (without showing the format)
- Mix analytical and executive content in the same section: Separate technical details from high-level insights
The process reflection helps you understand the LLM’s analytical reasoning and identify potential issues like non-normal distributions that might affect result validity.
Example Output Structure:
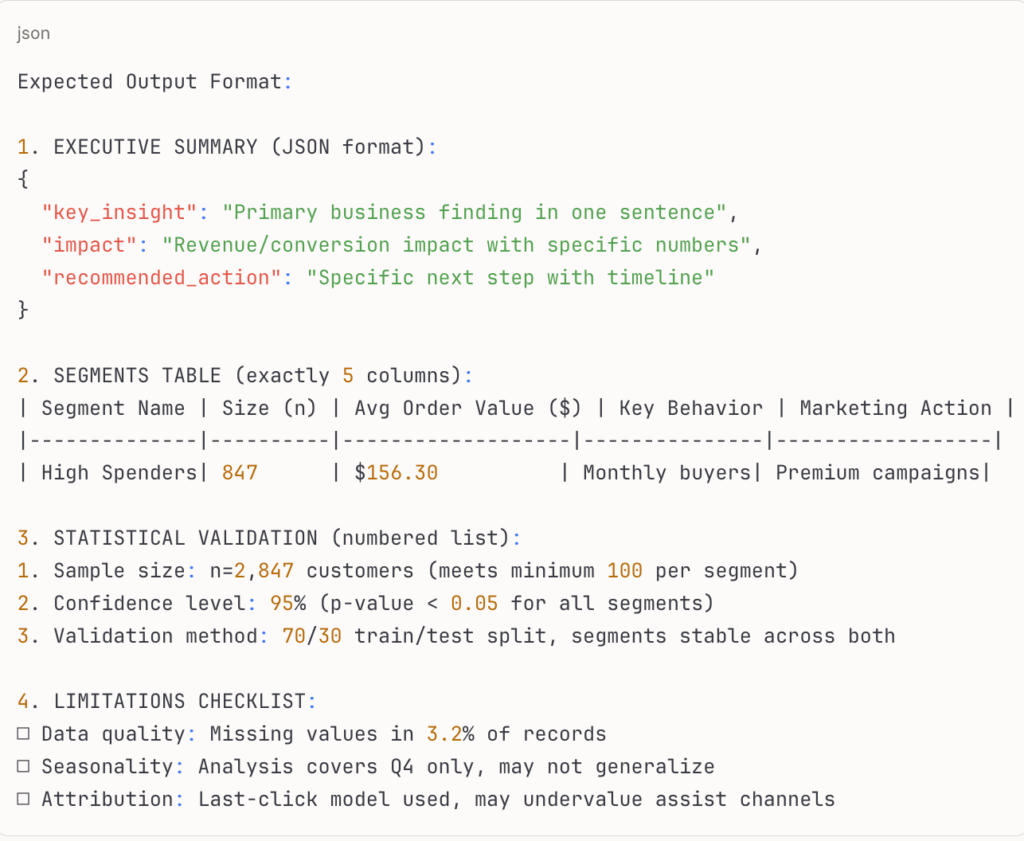
This structured approach ensures your AI delivers analysis that’s immediately usable for both technical review and stakeholder presentations.
Prompting Success at Scale
Use a consistent framework across all your analytical prompts to handle queries ranging from simple requests like “show me descriptive statistics” to complex analytical tasks like “create a new table with unique DMA values from all sheets except DMA master” or “perform a comprehensive skewness analysis with business interpretation.”
Advanced Prompting: Chain of Analytical Reasoning
For complex analyses, structure your prompts to mirror professional analytical thinking:
What TO Do:
- Build analytical workflows that follow logical progression
- Require documentation at each reasoning step
- Include validation checkpoints throughout the process
- Specify when to escalate to human expert review
What NOT To Do:
- Don’t jump straight to calculations without understanding the business problem
- Avoid skipping data quality assessment steps
- Never accept results without reasonableness checks
- Don’t present findings without acknowledging limitations
Validation & Limitations: Critical thinking!
– Cross-check results for business logic
– Document any caveats or limitations
– Flag and check unusual patterns requiring domain expertise
– Always check if results contradict expected business logic
Example Analytical Chain Prompt Structure:
Follow this analytical reasoning chain for complex analyses:
STEP 1: Problem Understanding
– Restate the business question in your own words
– Define success criteria for this analysis
– Output format: “Business Question: [restatement]”
STEP 2: Data Assessment
– Evaluate data quality, completeness, missing values
– Check for outliers or anomalies
STEP 3: Methodology Selection
– Use the method you would use manually
– If you don’t know, ask for options and justification of these options
– Show intermediate steps for verification
Validation & Limitations: Critical thinking!
– Cross-check results for business logic
– Document any caveats or limitations
– Flag and check unusual patterns requiring domain expertise
– Always check if results contradict expected business logic
STEP 4: Business Translation
– Convert analytics findings to business insights
– Include practical significance alongside analytics significance
OK I won’t repeat that any more but I really think it’s worth repeating it three times…
Validation & Limitations: Critical thinking!
– Cross-check results for business logic
– Document any caveats or limitations
– Flag and check unusual patterns requiring domain expertise
– Always check if results contradict expected business logic
Beyond Prompting: RiffML and Dynamic Context Injection
While systematic prompting solves many analytical AI challenges, it still has limitations. Complex multi-step analyses require context that changes dynamically. Variables from one analytical step need to flow seamlessly into the next. Error handling requires branching logic that simple prompts can’t accommodate.
This is where advanced context engineering frameworks like RiffML (Reasoning Interactive Flow Framework Markup Language) become essential for serious analytical work.
What RiffML Enables for Analytics
RiffML is an XML-based orchestration language designed specifically for AI agents handling complex workflows. For AI Analysts, it solves three critical problems that prompting alone cannot address:
1. Dynamic Context Injection with Variables
Instead of static prompts, RiffML enables dynamic context that adapts based on analytical discoveries:
“`xml
<phase name=”understand_request”>
<!– Persistent instructions across all LLM calls –>
<instruct history=”core”>
You help users analyze data. Available tables: ${project.catalog.models}
Current session context: ${session.analysis_plan}
</instruct>
<!– Conditional context based on analysis type –>
<instruct history=”financial” security=”read:financial.detailed”>
You can access detailed margin data: ${financial.schemas}
Previous financial analyses: ${memory.financial_patterns}
</instruct>
<!– Dynamic flow control based on discovered needs –>
<if condition=”${session.analysis_plan.requires_statistical_validation}”>
<next phase=”validate_statistical_assumptions”/>
</if>
</phase>
“`
2. Context Memory That Learns from Outcomes
Traditional prompting loses context between sessions. RiffML includes JAM (Joint Associative Memory) that tracks which context actually leads to successful analytical outcomes:
“`xml
<state name=”customer_segmentation_analysys”>
For segmentation analysis, users typically need:
– Current customer behavioral data (${data.customer_behavior})
– Historical transaction patterns (${memory.successful_segmentation_context})
– Business constraints: ${business.segmentation_requirements}
Exclude: marketing campaign data, product inventory
Success rate with this context combination: 87%
</memory>
“`
3. Semantic Security for Data Governance
Analytics requires accurate and safe data access controls. RiffML’s SWING framework provides semantic security with tag-based permissions, to ensure that prompts can only run tools and query data under the permissions of the user and project scope:
“`xml
<!– Tool execution respects user permissions and data classification –>
<RunTool tool=”query_database”
security=”read:data.sales.aggregated,exclude:customer.pii”
input=”${session.validated_query}”>
SELECT region, SUM(revenue) FROM sales
WHERE date >= ‘${analysis.date_range.start}’
GROUP BY region
</RunTool>
<!– State access enforces business logic –>
<state name=”project.customer_segments”
security=”resource:data.behavioral,purpose:segmentation_analysis”>
${load_customer_behavioral_data()}
</state>
“`
Variable Injection in Action
Here’s how RiffML handles a complex analytical request with dynamic context:
Here’s the reduced version:
“Here’s how RiffML handles a complex analytical request with dynamic context:
<riff name=”CustomerChurnAnalysis”>
<phase name=”data_assessment”>
<instruct>
Assess data quality for churn analysis using:
${project.tables.customers}, ${project.tables.transactions}
Requirements: ${business.churn_analysis_requirements}
</instruct>
<llm storeTarget=”assessment.data_quality”/>
</phase>
<phase name=”analysis_execution”>
<instruct>
Execute churn analysis with context:
– Data quality: ${assessment.data_quality}
– Previous patterns: ${memory.churn_analysis_success}
</instruct>
<RunTool tool=”statistical_analysis” input=”${methodology.selected_approach}”/>
</phase>
</riff>
“`”
Why This Matters for AI Analysts
RiffML represents a fundamental advancement beyond static prompting:
**Context Continuity**: Variables like `${assessment.data_quality}` and `${methodology.selected_approach}` ensure analytical context flows seamlessly between phases.
**Outcome-Based Learning**: The system learns from `${memory.churn_analysis_success}` which can be applied to improve analysis and LLM accuracy in future similar settings.
**Dynamic Adaptation**: Conditional logic like `<if condition=”${assessment.data_quality.completeness} < 0.8″>` enables error handling and more efficient and accurate prompts.
**Security Integration**: Semantic permissions like `security=”read:customer.behavioral,write:analysis.results”` maintain governance throughout complex workflows.
If you are still reading this and are interested in RiffMl, we are considering open sourcing it. Let us know if you’d like to collaborate.
The Future of Analytics Context Engineering
The evolution from prompting to systematic context engineering represents a fundamental shift in how AI Analysts work. While prompting techniques provide the foundation, advanced frameworks enable:
– Multi-session memory that preserves analytical learnings across projects
– Dynamic context injection that adapts to analytical discoveries in real-time
– Semantic security that enforces data governance automatically
– Collaborative orchestration where domain experts define methodology while AI handles implementation
As an AI Analyst, mastering systematic prompting is essential for immediate productivity. But understanding context engineering frameworks like RiffML prepares you for the next generation of analytical AI collaboration – where complex multi-step analyses become as manageable as simple queries, while maintaining the statistical rigor and business context that make analytics valuable.
The choice isn’t between prompting and advanced frameworks – it’s about using the right approach for the right analytical challenge. Start with systematic prompting to build your foundation, then explore context engineering frameworks when your analyses require the dynamic complexity that only variable injection and outcome-based learning can provide.
—
Katrin Ribant, CEO
Avigad Oron, Head of Technology
Yuval Bork, Product Manager
Link to the article on LinkedIn.